The Kubeflow 1.3 software release streamlines ML workflows and simplifies ML platform operations
- Streamlined ML workflows delivered via new UIs
- Infrastructure and operational efficiencies
- Simplified installation and improved documentation
- Kubeflow 1.3 tutorials
- Join the community
The Kubeflow 1.3 release delivers simplified ML workflows and additional Kubernetes integrated features to optimize operational and infrastructure efficiencies. In addition to new User Interfaces (UIs), which improve ML workflows for pipeline building, model tuning, serving and monitoring, 1.3 also enables “headless” GitOps-inspired installation patterns. The latest version of Kubeflow provides users with a mature foundation and delivers a modern ML platform with best-in-class Key Performance Indicators (KPIs).
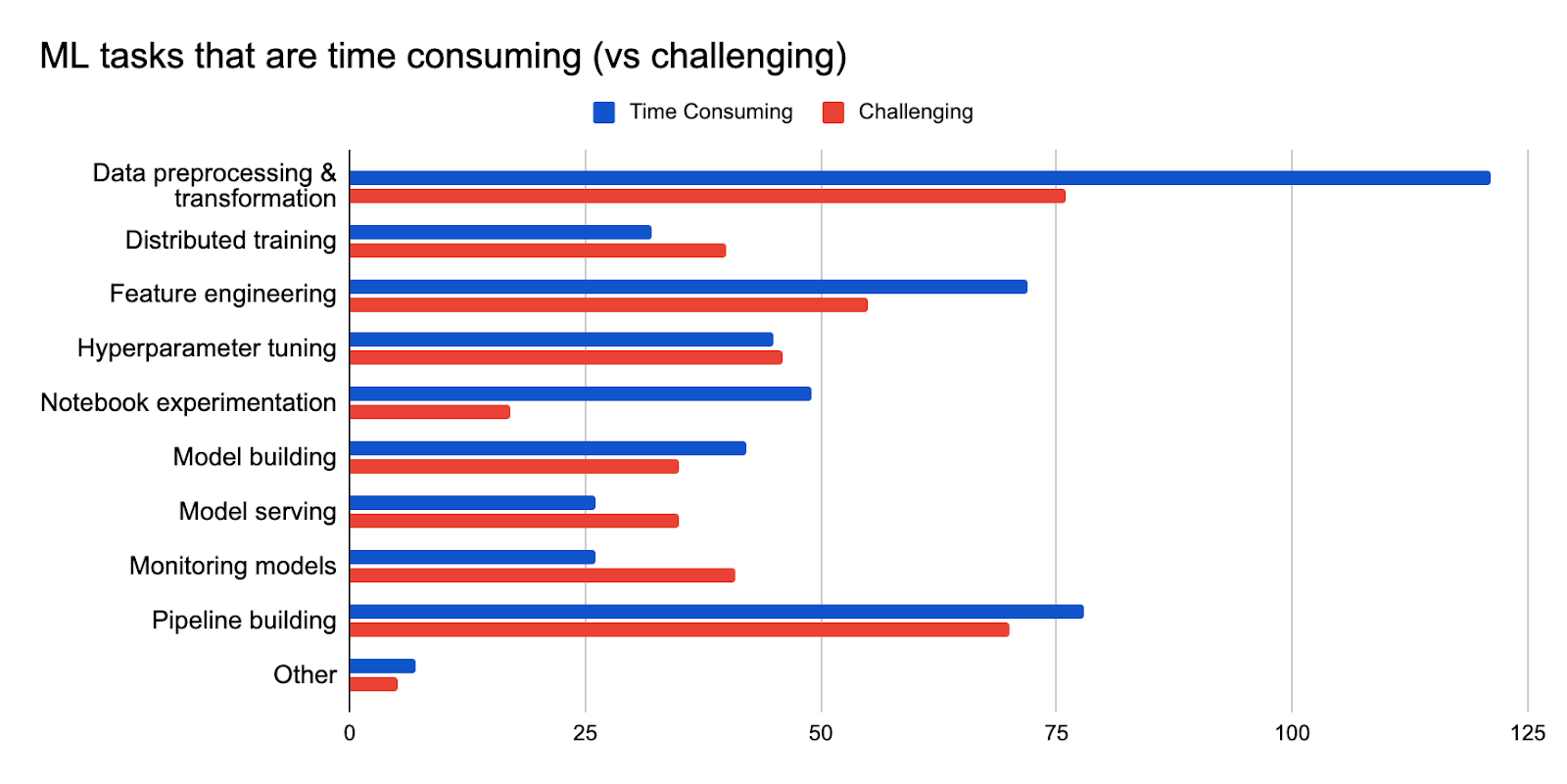
The Kubeflow user community is growing quickly, which was demonstrated in our recent survey results. When compared to last year’s survey, the 2021 Survey showed a 50% increase in responses and a whopping 300% increase in users supporting production deployments. As shown below, the user survey responses, especially from ML engineers, architects and data scientists, have identified where the Kubeflow contributors should focus their efforts.
Kubeflow User Survey Results - March 2021
Streamlined ML workflows delivered via new UIs
Data scientists will like the new and updated user interfaces (UIs) for Katib, TensorBoard, Persistent Volumes, Pipelines and Kale. These new UIs address many of the ML tasks that are time consuming and technically challenging. The UIs reduce the need for a data scientist to learn kfctl or docker CLI commands.
Below please find details on the UIs’ benefits for ML workflows:
- Katib (Video Tour)
- The Katib UI is integrated with the central dashboard and streamlines hyperparameter tuning by presenting a visualization graph and a table that compares each trial’s performance along with its hyperparameters. You can also review the details of each trial’s algorithm, metrics collector and yaml. (Project 1)
- TensorBoard (Video tour)
- The TensorBoard UI streamlines the TensorBoard configuration tasks, especially for logging of training jobs which are running in Notebooks or Pipelines. It simplifies accessibility to metrics, which helps you to improve model accuracy , identify performance bottlenecks, and reduce unproductive training jobs.
- Volume Manager (Video tour)
- The Volume Manager enables you to manage your data and persistent volumes. For the volumes in your namespace, it streamlines the creation and deletion of volumes, which then can be easily attached to your notebooks. PR 5684
- Kale (Video tour)
- The updated Kale UI, a JupyterLab extension, simplifies your hyperparameter tuning trial set-up. The UI walks you through these steps: enter your hyperparameters as a list or a range, pick your search algorithm (Grid, Random, Bayesian) and the parameter to be optimized i.e. minimize loss. Then with a click of a button, your Katib trials are set-up, snapshotted, tracked, and run.
- Kubeflow Pipelines (KFP)
Beyond the UIs, data scientists can also tie Notebooks with Serving more closely than ever before. In addition to the aforementioned integration with TensorBoard, Kubeflow Notebooks also now support first class deployments with TensorFlow 2.0, PyTorch, VS Code and RStudio.
KFServing enhancements include simplified canary rollouts with traffic splitting at the Knative revisions level. It also delivers extended ML framework support for:
- TorchServe predict and PyTorch Captum Explain
- PMMLServer, PR 1141
- LightGBM
Infrastructure and operational efficiencies
ML engineers will like 1.3’s delivery of operational and infrastructure efficiencies, which are coupled with streamlined installation patterns and upgraded Istio version support. The following chart provides a summary of the top production features in 1.3.
| Feature | Benefits |
| Multi-model serving (Alpha) | More models on same infra and workaround cluster limits i.e. # of pods & ip addresses |
| Pod affinity | Avoid unnecessary usage on GPU or large CPU nodes |
| gRPC support | Fewer messages, less bandwidth for KFServing workloads |
| Katib trial templates | Simplifies hyperparameter tuning set-up for custom model types |
| Katib early stopping | Stops hyperparameter tuning trials that are unproductive |
| Pipelines step caching | Re-use results from previously run steps |
| Multi-user pipelines | User and resource isolation for non-GCP environments. |
| Manifests refactoring | Simplifies Kubeflow installation and upgrades |
| Istio upgradability | Improved security, day 2 operations, compatibility and support |
We are pleased to announce that the user documentation on Kubeflow.org has also been updated (PR 2546). Additional detailed documentation, especially on the valuable working group deliveries, can be found here:
- Kubeflow Pipeline 1.3 Project (PR 12)
- Kubeflow Pipelines SDK with Tekton
- Operationalize, scale and infuse trust in AI models using KFServing
- Kubeflow Katib: Scalable, portable and cloud native system for AutoML
Simplified installation and improved documentation
ML Engineers, who are installing Kubeflow, have a clear path to installation success as Kubeflow 1.3 includes new manifests and upgraded Istio support. For more information on installation patterns for each distribution, please visit the Getting Started page on Kubeflow.org. If you are supporting a distribution or just interested in low-level details, please review the Kubeflow 1.3 Manifest readme.
Kubeflow 1.3 tutorials
Kubeflow 1.3 new features are easy to try on these tutorials:
- Open Vaccine Tutorial
- Use the new UIs to build an ML Pipeline, tune your model, and then deploy and monitor it. This tensorflow-based example was modified from a Kaggle tutorial for building a Covid 19 vaccine from bases in an mRNA molecule. The tutorial is easy to run on AWS and GCP in about 1 hour.
- Model Risk Management Tutorial
- This model produces a SR11-7 compliance report for financial institutions who are regulated by the Federal Reserve. The example provides reporting on bias in a home mortgage lending model. The tutorial is easy to run on AWS and GCP in about 1 hour.
Join the community
We would like to thank everyone for their efforts on Kubeflow 1.3, especially the code contributors and working group leads. As you can see from the extensive contributions to Kubeflow 1.3, the Kubeflow Community is vibrant and diverse, and solving real world problems for organizations around the world.
Want to help? The Kubeflow Community Working Groups hold open meetings, public lists, and are always looking for more volunteers and users to unlock the potential of machine learning. If you’re interested in becoming a Kubeflow contributor, please feel free to check out the resources below, we look forward to working with you!
- Visit our Kubeflow website or Kubeflow GitHub Page
- Join the Kubeflow Slack channel
- Join the kubeflow-discuss mailing list
- Attend a weekly community meeting