Operationalize, Scale and Infuse Trust in AI Models using KFServing
KFServing 0.5 Blog Post
By Animesh Singh and Dan Sun
With inputs from : KFServing WG, including Yuzhui Liu, Tommy Li, Paul Vaneck, Andrew Butler, Srinivasan Parthasarathy etc.
Machine Learning has become a key technology in a wide range of industries and organizations. One key aspect in ML landscape is that more and more models are getting produced, but are they actually getting deployed? And if they are getting deployed, are there enough robust operational mechanisms in place to understand model predictions, and monitor for drift, accuracy, anamoly, bias etc.? One key aspect of deploying models in production is being able to monitor the predictions for various metrics, and explaining the decisions the model is making, and producing quality metrics, more so in regulated industries like finance, healthcare, government sector etc. Additionally based on those metrics do we have a technology in place to understand the metrics and take corrective actions e.g. doing canary rollouts?
KFServing, a project which originated in the Kubeflow community, has been hard at work solving production model serving use cases by providing performant, high abstraction interfaces for common ML frameworks like Tensorflow, XGBoost, ScikitLearn, PyTorch, and ONNX. It encapsulates the complexity of autoscaling, networking, health checking, and server configuration to bring cutting edge serving features like GPU Autoscaling, Scale to Zero, and Canary Rollouts to model deployments. We just released KFServing v0.5 with other various features to address the model operationalization and trust needs. Additionally, the team has been hard at work to make AI explainability a core construct of the deployed models, by integrating with various industry leading technologies.
KFServing Beta API and V2 (next gen) Inference Protocol
KFServing 0.5 has promoted the control plane API from v1alpha2 to stable v1beta1 and started to support the data plane V2 inference protocol. The v1beta1 control plane API enables a simple, data scientist-friendly interface, while providing the flexibility of specifying container and pod template fields for pre-packaged model servers. The V2 inference protocol pushes a standard and easy-to-use high performance REST/gRPC API across multiple model servers, such as Triton and MLServer, to increase the portability of the model ensuring the client/server can operate seamlessly.
KFServing 0.5 also introduces an optional model agent for request/response logging, request batching, and model pulling. The model agent sits alongside as a sidecar to the model server. Pre-packaged Model servers plugged onto KFServing can benefit from these common model serving features, as well as the model servers built using custom frameworks.
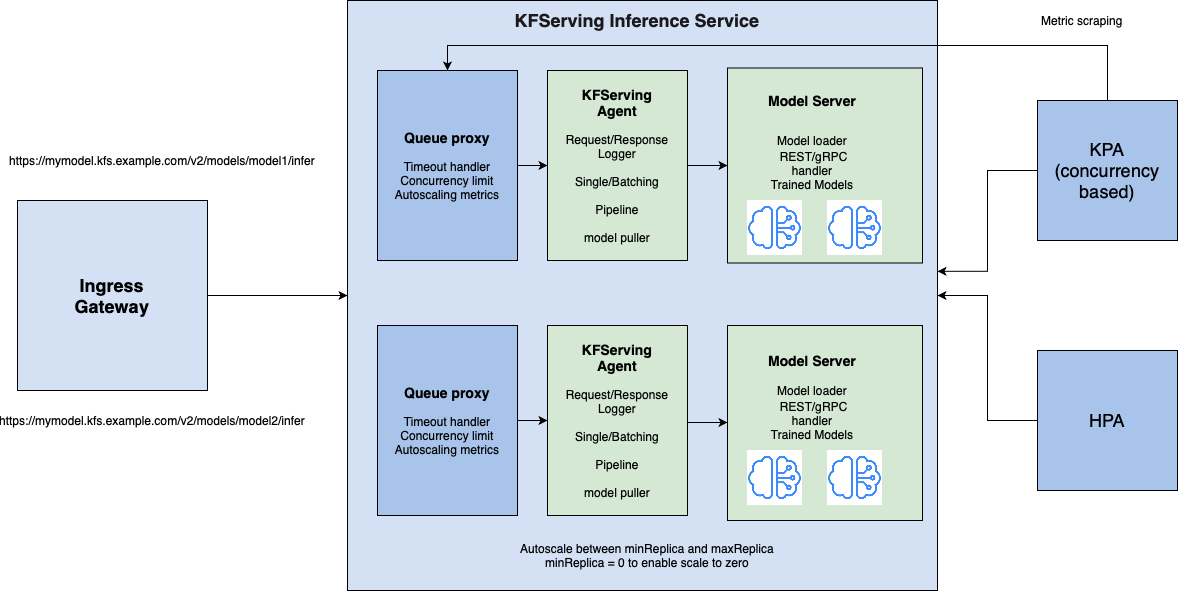
What’s New?
-
TorchServe integration: TorchServe now is used as implementation for KFServing PyTorch model server, it also enables model explanability with Captum, see TorchServe examples here.
-
Triton Inference Server V2 inference REST/gRPC protocol support, see examples of serving BERT and TorchScript models on GPUs.
-
Tensorflow gRPC support.
-
SKLearn/XGBoost model server now uses MLServer which supports v2 inference protocol.
-
You can now specify container or pod template level fields on the pre-packaged model servers (e.g., env variables, readiness/liveness probes).
-
Allow specifying timeouts on the component spec.
-
Simplified canary rollout, you no longer need to specify both the default and canary specs on the InferenceService spec; KFServing now automatically tracks the last rolled out revision and automatically splits the traffic between the latest ready revision and last rolled out revision.
-
The transformer to predictor call now defaults to using AsyncIO, which significantly improves the latency/throughput for high concurrent workload use cases.
KFServing Multi-Model Serving to enable massive scalability
With machine learning approaches becoming more widely adopted in organizations, there is a trend to deploy a large number of models. The original design of KFServing deploys one model per InferenceService. But when dealing with a large number of models, its ‘one model, one server’ paradigm presents challenges on a Kubernetes cluster to deploy hundreds of thousands of models. To scale the number of models, we have to scale the number of InferenceServices, something that can quickly challenge the cluster’s limits.
Multi-model serving is an alpha feature added in 0.5 to increase KFServing’s scalability. To learn more about multi-model serving motivations and implementation deatils, dive into the details in KFServing github. Please assume that the interface is subject to change. The experimental feature must be enabled from the inference service configmap.
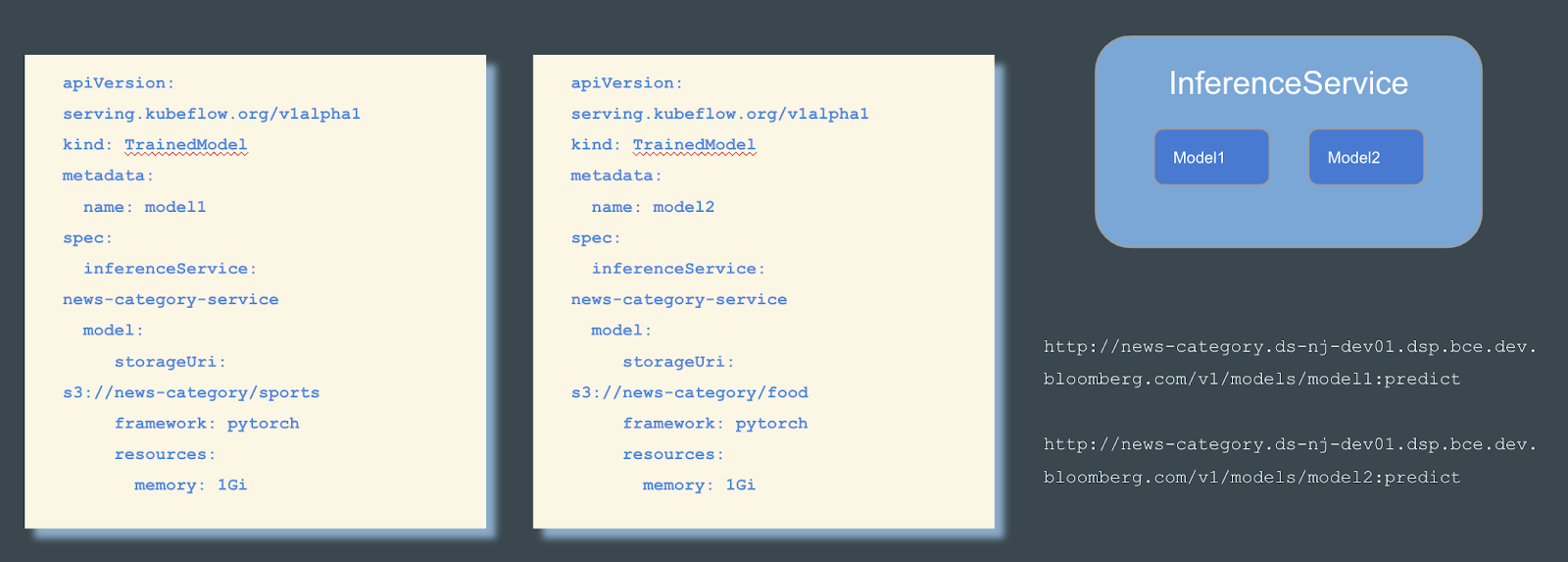
Multi-model serving will work with any model server that implements KFServing’s V2 protocol. More specifically, if the model server implements the load and unload endpoint, then it can use KFServing’s TrainedModel. Currently, the supported model servers are Triton, SKLearn, and XGBoost. Click on Triton or SKLearn for examples on how to run Multi-Model Serving.
KFServing on OpenShift
RedHat OpenShift is a market leader for enterprise Kubernetes distribution, and by enabling KFServing for OpenShift we have ensured that enterprises running battle hardened OpenShift platform can leverage KFServing to bring serverless model inferencing on OpenShift, including how to leverage OpenShift Service Mesh. Please follow the details here to get KFServing running on OpenShift

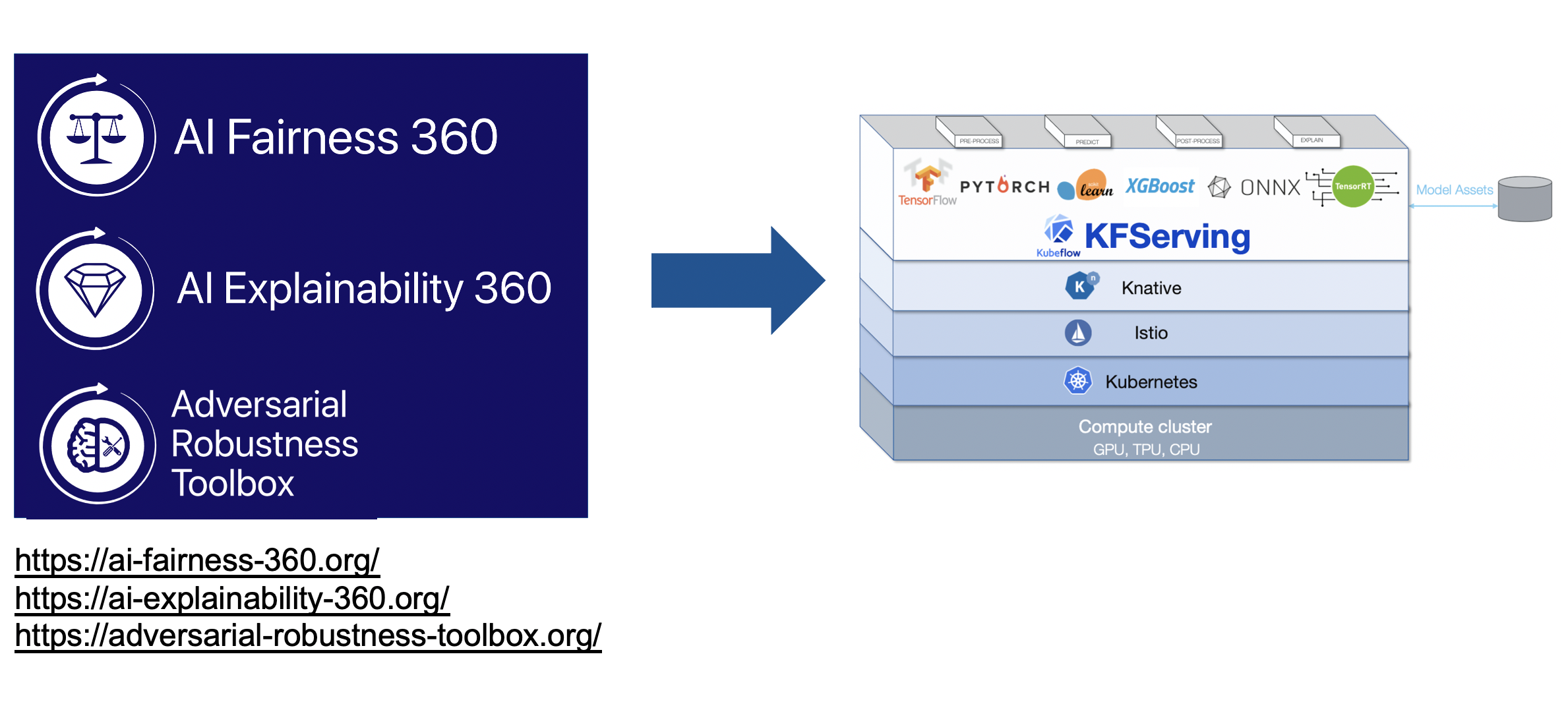
LFAI Trusted AI Projects on AI Fairness, AI Explainability and Adversarial Robustness in KFServing
Trust and responsibility should be core principles of AI. The LF AI & Data Trusted AI Committee is a global group working on policies, guidelines, tools and projects to ensure the development of trustworthy AI solutions, and we have integrated LFAI AI Explainability 360, Adversarial Robustness 360 in KFServing to provide production level trusted AI capabilities. Please find more details on these integration in the following links
AI Explainability 360-KFServing Integration
AI Fairness 360-KFServing Integration
Adversarial Robustness Toolbox-KFServing Integration
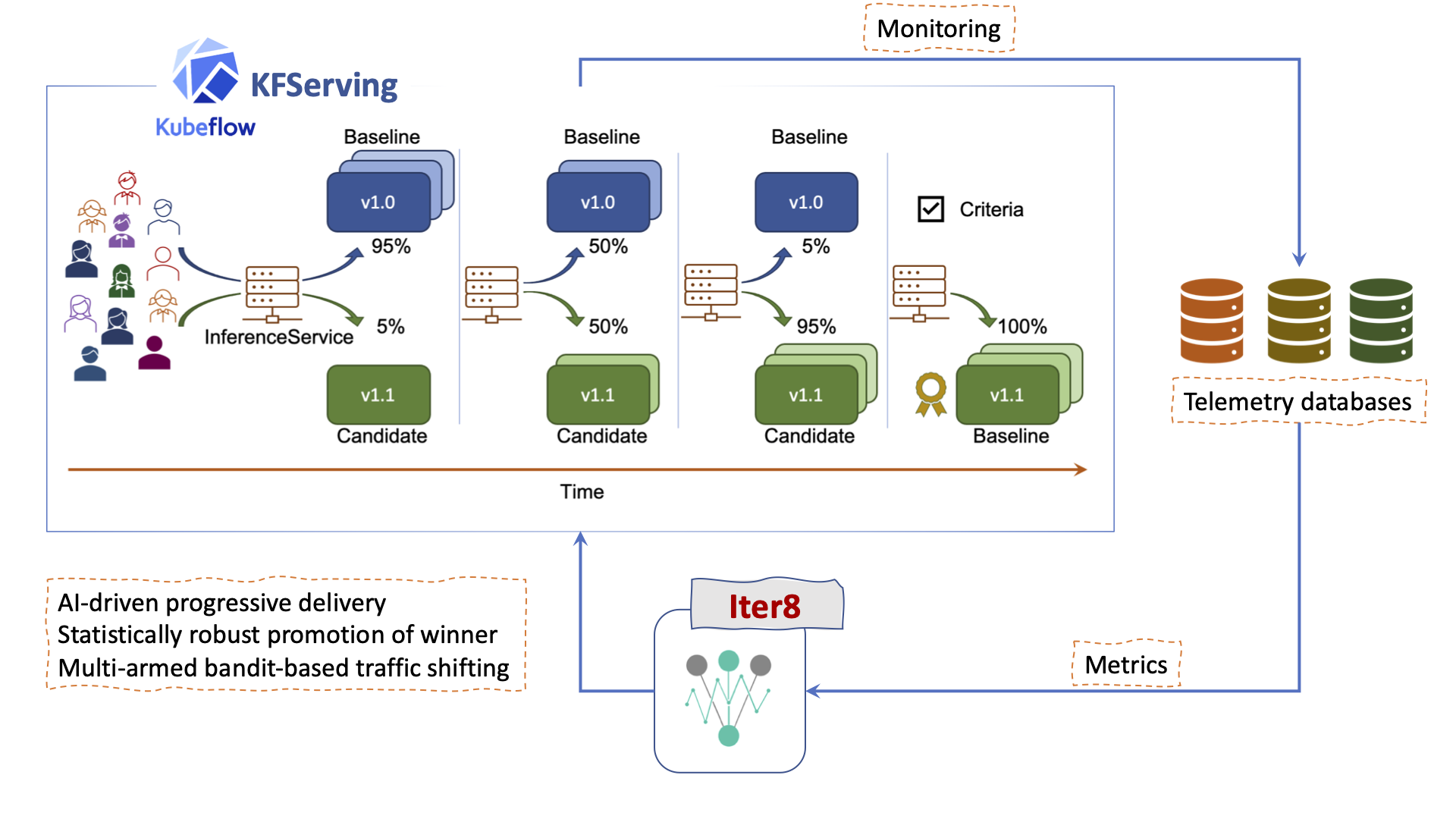
Metrics driven automated rollouts using Iter8 in KFServing
Iter8-KFServing enables metrics-driven experiments, progressive delivery, and automated rollouts for ML models served over Kubernetes and OpenShift clusters. Iter8 experiments can be used to safely expose competing versions of a model to traffic while gathering and assessing metrics to intelligently shift traffic to the winning version of your model. Discover how to set it up and get it running in the Iter8-KFServing repository
Join us to build Trusted Model Inferencing Platform on Kubernetes
Please join us on the KFServing GitHub repository, try it out, give feedback, and raise issues. Additionally, you can connect with us via the following:
-
To contribute and build an enterprise-grade, end-to-end machine learning platform on OpenShift and Kubernetes, please join the Kubeflow community and reach out with any questions, comments, and feedback!
-
If you want help deploying and managing Kubeflow on your on-premises Kubernetes platform, OpenShift, or on IBM Cloud, please connect with us.
-
Check out the OpenDataHub if you are interested in open source projects in the Data and AI portfolio, namely Kubeflow, Kafka, Hive, Hue, and Spark, and how to bring them together in a cloud-native way.
Contributor Acknowledgement
We’d like to thank all the KFServing contributors for the awesome work!