Kubeflow Katib: Scalable, Portable and Cloud Native System for AutoML
Katib 0.10 Blog Post
As machine learning (ML) architectures are increasing in complexity, it is becoming important to find the optimal hyperparameters and architecture for ML models. Automated machine learning (AutoML) has become a crucial step in the ML lifecycle. Katib provides AutoML features in Kubeflow in a Kubernetes native way.
Katib is an open source project which is agnostic to ML frameworks. It can tune hyperparameters in applications written in any language of the user’s choice and natively supports many ML frameworks, such as TensorFlow, Keras, PyTorch, MPI, MXNet, XGBoost, scikit-learn, and others. Katib improves business results by efficiently building more accurate models and lowering operational and infrastructure costs. Katib can be deployed on local machines, or hosted as a service in on-premise data centers, or in private/public clouds.
Katib offers a rich set of features accessible via APIs. By using these APIs, Katib is natively integrated to Kubeflow Notebooks and Pipelines. Katib supports Hyperparameter optimization (HP), Neural Architecture Search (NAS), and Early Stopping. Early Stopping feature can be used without any significant changes in the current Katib Experiments.
Furthermore, Katib is a unique system which supports all Kubernetes workloads and Kubernetes custom resource definition (CRD) to perform Katib Experiments. Since Katib can execute various Kubernetes resources, users are able to run not only ML models optimization Experiments. They can also enhance any software, code or program to make it more efficient with optimization algorithms provided by Katib.
We are continually working on the new Katib UI to provide a better User Experience and native integration with Kubeflow central dashboard. Please check this presentation to know more about the new UI.
All of the above mentioned features allow users to easily integrate Katib in their ML infrastructure pipeline.
System Architecture
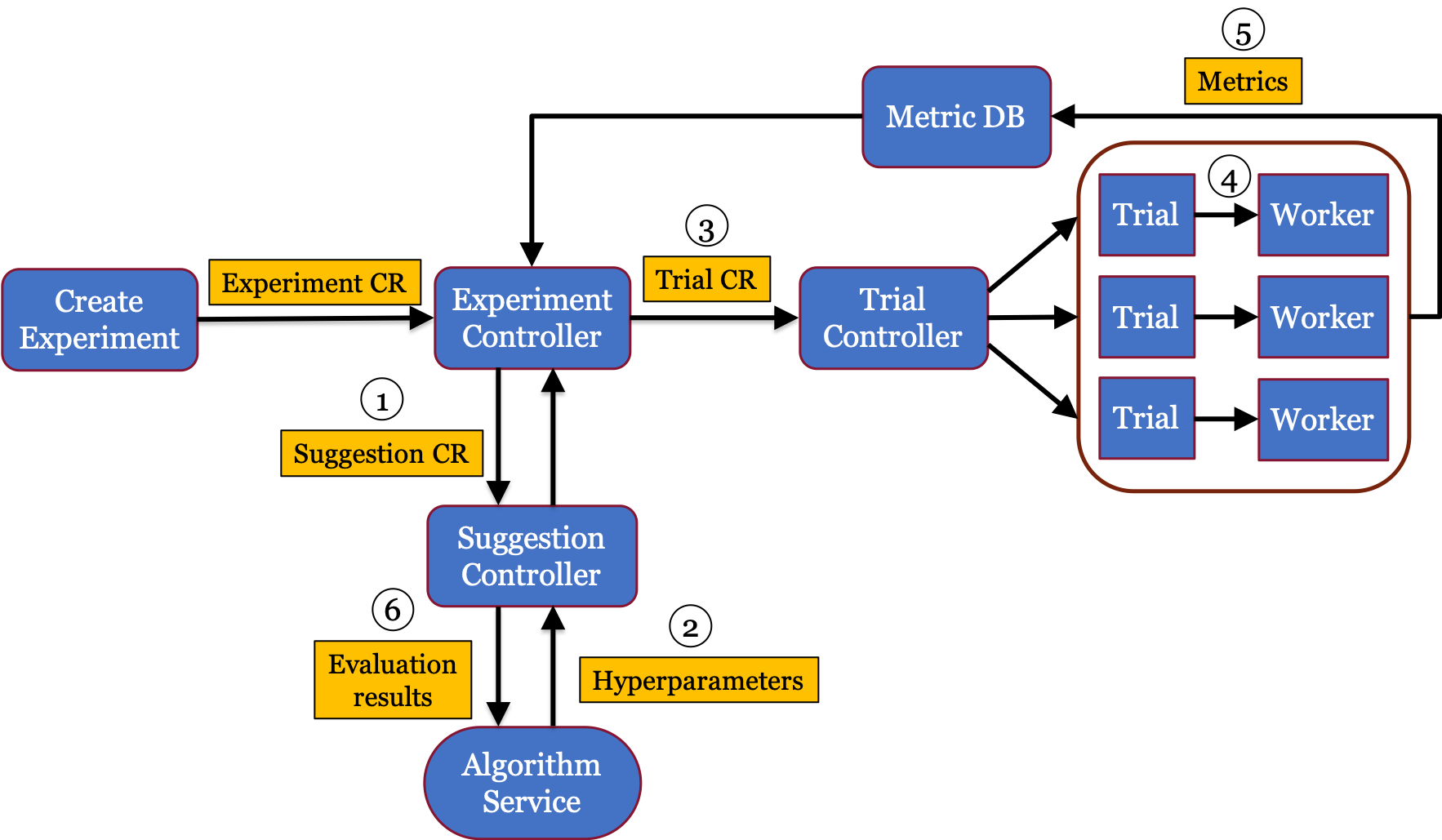
There are 3 main concepts in Katib which are Kubernetes CRDs:
-
Experiment - a single optimization run with objective, search space, and search algorithm.
-
Suggestion - set of hyperparameters, which are produced by a user’s selected search algorithm. Katib creates Trials to evaluate them.
-
Trial - one iteration of the hyperparameters tuning process. Trial runs the worker job which corresponds to the training job. Since Trial is an abstraction on top of the worker job, any Kubernetes resource can be used to perform the training job. For example, TFJob, MPIJob or even Tekton Pipeline.
By using above resources Katib follows the following steps, which are marked in the diagram above:
-
Once an Experiment is submitted, the Experiment controller creates an appropriate Suggestion object.
-
The Suggestion controller creates an AutoML algorithm service based on this Suggestion object. When the algorithm service is ready, the Suggestion controller calls the service to get new parameters and appends them to the Suggestion object.
-
The Experiment controller finds that Suggestion object has been updated and creates a corresponding Trial object for each set of parameters.
-
The Trial controller generates a worker job for each Trial object and watches for the status of each job. The worker job based on the Trial template.
-
Once the worker job has been completed, the metrics collector gets the metrics from the job and persists them in the database.
-
The Experiment controller sends the metrics results to the algorithm service and gets new parameters from the Suggestion object.
Custom Kubernetes resources support
Katib version 0.10 implements a new feature to support any Kubernetes CRDs or Kubernetes workloads as a Katib Trial template. Therefore, there is no need to manually modify the Katib controller to use CRD as a Trial. As long as the CRD creates Kubernetes Pods, allows injecting the sidecar container on these Pods, and has success and failure status, the CRD can be used in Katib.
Here are the motivations behind this feature:
-
Katib Trial template supports only a limited type of Kubernetes resource (BatchJob, TFJob and PyTorchJob).
-
Many Katib users might have their own CRDs which they want to use as a Trial template. Thus, the approach of updating the Katib controller for the new CRD is not scalable.
-
Some CRDs might have Go packages versions which are incompatible with the Katib controller packages. For such cases, it is impossible to build a Katib controller image.
-
Users have to build and maintain a custom image version for the Katib controller if they want to implement a new CRD in Katib.
The above problems led to the creation of a scalable and portable solution for the Trial template. This solution allows users to modify Katib components and to add their CRDs without changing the Katib controller image.
Katib now supports Tekton Pipeline and MPIJob in addition to BatchJob, TFJob and PyTorchJob. In the case of Tekton Pipeline, a user is able to build a complex workflow inside the Trial’s worker job. The user also can implement data preprocessing and postprocessing with all of the Tekton Pipeline features. Eventually, Katib’s metrics collector parses and saves the appropriate metrics from the training processes to the database.
Support new Kubernetes CRD in Katib
To support new Kubernetes CRD, Katib components need to be modified before installing in the Kubernetes cluster. To make this modification, it is necessary to know:
-
what API group, version, and kind the Kubernetes CRD has, and
-
which Kubernetes resources the CRD’s controller creates.
Check the Kubernetes guide to know more about CRDs.
Follow these two simple steps to integrate new CRD in Katib:
-
Modify the Katib controller Deployment’s arguments with the new flag:
--trial-resources=<object-kind>.<object-API-version>.<object-API-group>For example, to support Tekton Pipeline:
. . . containers: - name: katib-controller image: docker.io/kubeflowkatib/katib-controller command: ["./katib-controller"] args: - "--webhook-port=8443" - "--trial-resources=Job.v1.batch" - "--trial-resources=TFJob.v1.kubeflow.org" - "--trial-resources=PyTorchJob.v1.kubeflow.org" - "--trial-resources=MPIJob.v1.kubeflow.org" - "--trial-resources=PipelineRun.v1beta1.tekton.dev" . . . -
Modify the Katib controller ClusterRole’s rules with the new rule to give Katib an access to all Kubernetes resources that are created by the CRD’s controller. To know more about ClusterRole, please check the Kubernetes guide.
For example, for the Tekton Pipeline, Trial creates Tekton PipelineRun, then Tekton PipelineRun creates Tekton TaskRun. Therefore, Katib controller ClusterRole should have an access to the pipelineruns and taskruns:
kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: katib-controller rules: - apiGroups: - tekton.dev resources: - pipelineruns - taskruns verbs: - "*" - apiGroups: - kubeflow.org resources: - tfjobs - pytorchjobs - mpijobs verbs: - "*" . . . -
Install Katib by following the getting started guide.
At this point, the Kubernetes CRD can be used in the Katib Trial template. Check this guide to know more about Tekton and Katib integration.
Early Stopping
Early Stopping is now supported in the Katib 0.10 release. Early Stopping is one of the essential steps for doing HP tuning. It helps to avoid overfitting when the model is training during Katib Experiments.
Using Early Stopping helps to save compute resources and to reduce the Experiment execution time by stopping the Experiment’s Trials when the target metric(s) no longer improves before the training process is complete.
The major advantage of using Early Stopping in Katib is that
the training container package
doesn’t need to be modified. Basically, the Experiment’s YAML has to be extended
with the new entity - earlyStopping, which is similar to the algorithm YAML section:
apiVersion: "kubeflow.org/v1beta1"
kind: Experiment
metadata:
namespace: kubeflow
name: median-stop
spec:
algorithm:
algorithmName: random
earlyStopping:
algorithmName: medianstop
algorithmSettings:
- name: min_trials_required
value: "3"
- name: start_step
value: "5"
objective:
type: maximize
goal: 0.99
objectiveMetricName: Validation-accuracy
additionalMetricNames:
- Train-accuracy
parallelTrialCount: 2
maxTrialCount: 15
maxFailedTrialCount: 3
. . .
Currently, Katib supports the Median Stopping Rule. The Medium Stopping rule stops a running Trial at the step S if the Trial’s best objective value is lower than the median value of all succeeded Trials’ objectives reported up to that step S. Readers interested in learning more about the Median Stopping Rule can check the Google Vizier: A Service for Black-Box Optimization paper.
To know more about using Early Stopping in Katib please follow the official guide.
Getting Involved
First of all, thanks a lot to our contributors (Alfred Xu (Nvidia), Andrey Velichkevich (Cisco), Anton Kirillov (Mesosphere), Ce Gao (Tencent Cloud), Chenjun Zou (Alibaba), Elias Koromilas (InAccel), Hong Xu (IBM), Johnu George (Cisco), Masashi Shibata, Vaclav Pavlin (Red Hat), Yao Xiao (AWS), Yuan Tang (Ant Group)) who helped with the 0.10 release. Our community is growing and we are inviting new users and AutoML enthusiasts to contribute to the Katib project. The following links provide information about getting involved in the community:
-
Subscribe to the calendar to attend the AutoML WG community meeting.
-
Check the AutoML WG meeting notes.
-
Check the Katib adopters list.
-
Learn more about Katib in the presentations and demos list.
Please let us know about the active use-cases, feature requests and questions in the AutoML Slack channel or submit a new GitHub issue. To know more about the new Katib UI or to track the current integration process please check the GitHub project. We are planning to arrange a webinar and tutorial session for using AutoML in Kubeflow soon. Please join the kubeflow-discuss mailing list to know more about it.
Special Thanks to Amit Saha (Cisco), Ce Gao (Tencent Cloud), Johnu George (Cisco), Jorge Castro (Arrikto), Josh Bottum (Arrikto) for their help on this blog.