Data Science Meets Devops: MLOps with Jupyter, Git, & Kubernetes
An end-to-end example of deploying a machine learning product using Jupyter, Papermill, Tekton, GitOps and Kubeflow.
- The Problem
- Our Solution
- Background
- Putting It Together: Reconciler + GitOps = CI/CD for ML
- Build Your Own CI/CD pipelines
- What’s Next
- Conclusion
- Further Reading
The Problem
Kubeflow is a fast-growing open source project that makes it easy to deploy and manage machine learning on Kubernetes.
Due to Kubeflow’s explosive popularity, we receive a large influx of GitHub issues that must be triaged and routed to the appropriate subject matter expert. The below chart illustrates the number of new issues opened for the past year:
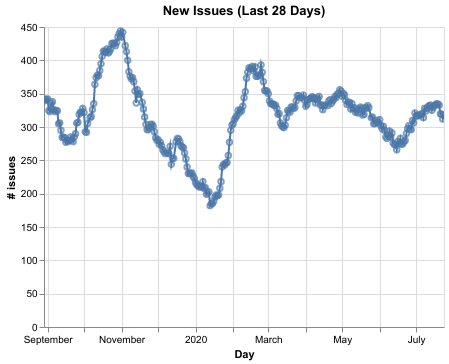
To keep up with this influx, we started investing in a Github App called Issue Label Bot that used machine learning to auto label issues. Our first model was trained using a collection of popular public repositories on GitHub and only predicted generic labels. Subsequently, we started using Google AutoML to train a Kubeflow specific model. The new model was able to predict Kubeflow specific labels with average precision of 72% and average recall of 50%. This significantly reduced the toil associated with issue management for Kubeflow maintainers. The table below contains evaluation metrics for Kubeflow specific labels on a holdout set. The precision and recall below coincide with prediction thresholds that we calibrated to suit our needs.
| Label | Precision | Recall |
|---|---|---|
| area-backend | 0.6 | 0.4 |
| area-bootstrap | 0.3 | 0.1 |
| area-centraldashboard | 0.6 | 0.6 |
| area-components | 0.5 | 0.3 |
| area-docs | 0.8 | 0.7 |
| area-engprod | 0.8 | 0.5 |
| area-front-end | 0.7 | 0.5 |
| area-frontend | 0.7 | 0.4 |
| area-inference | 0.9 | 0.5 |
| area-jupyter | 0.9 | 0.7 |
| area-katib | 0.8 | 1.0 |
| area-kfctl | 0.8 | 0.7 |
| area-kustomize | 0.3 | 0.1 |
| area-operator | 0.8 | 0.7 |
| area-pipelines | 0.7 | 0.4 |
| area-samples | 0.5 | 0.5 |
| area-sdk | 0.7 | 0.4 |
| area-sdk-dsl | 0.6 | 0.4 |
| area-sdk-dsl-compiler | 0.6 | 0.4 |
| area-testing | 0.7 | 0.7 |
| area-tfjob | 0.4 | 0.4 |
| platform-aws | 0.8 | 0.5 |
| platform-gcp | 0.8 | 0.6 |
Given the rate at which new issues are arriving, retraining our model periodically became a priority. We believe continuously retraining and deploying our model to leverage this new data is critical to maintaining the efficacy of our models.
Our Solution
Our CI/CD solution is illustrated in Figure 2. We don’t explicitly create a directed acyclic graph (DAG) to connect the steps in an ML workflow (e.g. preprocessing, training, validation, deployment, etc…). Rather, we use a set of independent controllers. Each controller declaratively describes the desired state of the world and takes actions necessary to make the actual state of the world match. This independence makes it easy for us to use whatever tools make the most sense for each step. More specifically we use
- Jupyter notebooks for developing models.
- GitOps for continuous integration and deployment.
- Kubernetes and managed cloud services for underlying infrastructure.
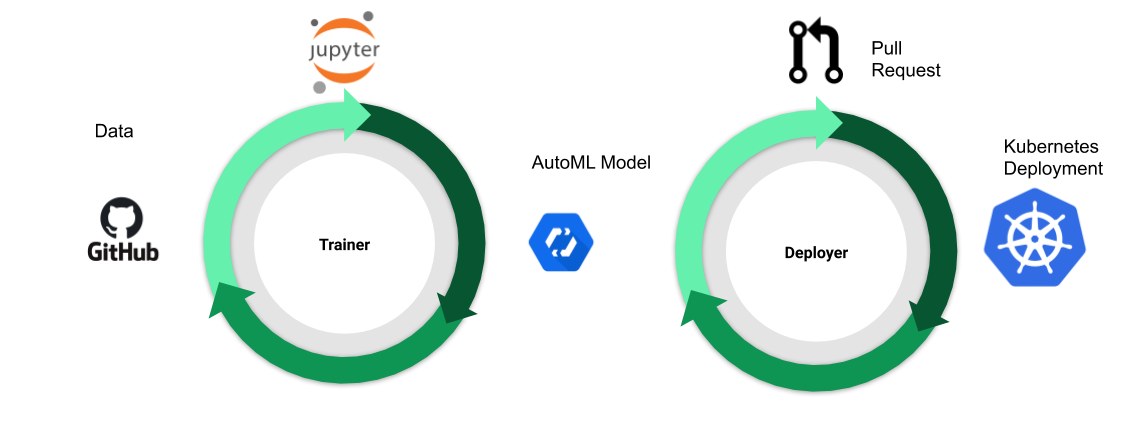
For more details on model training and deployment refer to the Actuation section below.
Background
Building Resilient Systems With Reconcilers
A reconciler is a control pattern that has proven to be immensely useful for building resilient systems. The reconcile pattern is at the heart of how Kubernetes works. Figure 3 illustrates how a reconciler works. A reconciler works by first observing the state of the world; e.g. what model is currently deployed. The reconciler then compares this against the desired state of the world and computes the diff; e.g the model with label “version=20200724” should be deployed, but the model currently deployed has label “version=20200700”. The reconciler then takes the action necessary to drive the world to the desired state; e.g. open a pull request to change the deployed model.
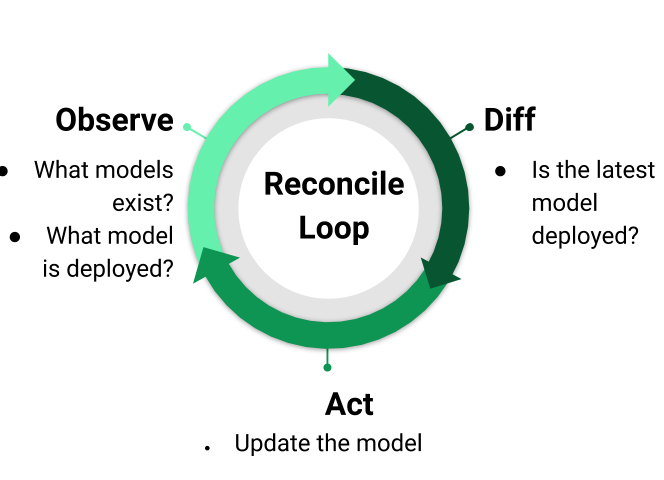
Reconcilers have proven immensely useful for building resilient systems because a well implemented reconciler provides a high degree of confidence that no matter how a system is perturbed it will eventually return to the desired state.
There is no DAG
The declarative nature of controllers means data can flow through a series of controllers without needing to explicitly create a DAG. In lieu of a DAG, a series of data processing steps can instead be expressed as a set of desired states, as illustrated in Figure 4 below:

This reconciler-based paradigm offers the following benefits over many traditional DAG-based workflows:
- Resilience against failures: the system continuously seeks to achieve and maintain the desired state.
- Increased autonomy of engineering teams: each team is free to choose the tools and infrastructure that suit their needs. The reconciler framework only requires a minimal amount of coupling between controllers while still allowing one to write expressive workflows.
- Battle tested patterns and tools: This reconciler based framework does not invent something new. Kubernetes has a rich ecosystem of tools that aim to make it easy to build controllers. The popularity of Kubernetes means there is a large and growing community familiar with this pattern and supporting tools.
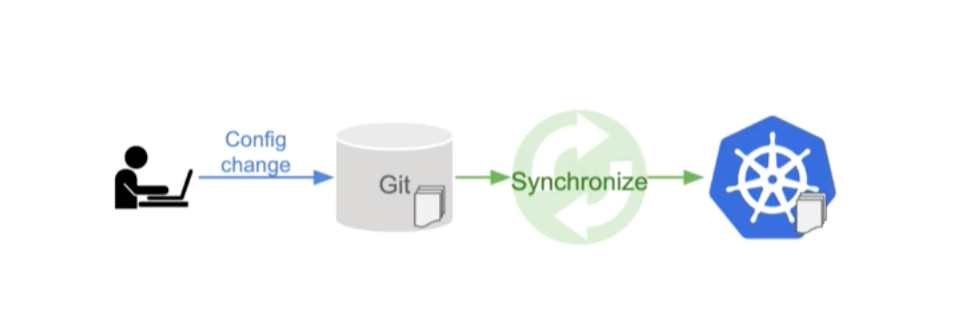
GitOps: Operation By Pull Request
GitOps, Figure 5, is a pattern for managing infrastructure. The core idea of GitOps is that source control (doesn’t have to be git) should be the source of truth for configuration files describing your infrastructure. Controllers can then monitor source control and automatically update your infrastructure as your config changes. This means to make a change (or undo a change) you just open a pull request.
Putting It Together: Reconciler + GitOps = CI/CD for ML
With that background out of the way, let’s dive into how we built CI/CD for ML by combining the Reconciler and GitOps patterns.
There were three problems we needed to solve:
- How do we compute the diff between the desired and actual state of the world?
- How do we affect the changes needed to make the actual state match the desired state?
- How do we build a control loop to continuously run 1 & 2?
Computing Diffs
To compute the diffs we just write lambdas that do exactly what we want. So in this case we wrote two lambdas:
- The first lambda determines whether we need to retrain based on the age of the most recent model.
- The second lambda determines whether the model needs to be updated by comparing the most recently trained model to the model listed in a config map checked into source control.
We wrap these lambdas in a simple web server and deploy on Kubernetes. One reason we chose this approach is because we wanted to rely on Kubernetes’ git-sync to mirror our repository to a pod volume. This makes our lambdas super simple because all the git management is taken care of by a side-car running git-sync.
Actuation
To apply the changes necessary, we use Tekton to glue together various CLIs that we use to perform the various steps.
Model Training
To train our model we have a Tekton task that:
- Runs our notebook using papermill.
- Converts the notebook to html using nbconvert.
- Uploads the
.ipynband.htmlfiles to GCS using gsutil
This notebook fetches GitHub Issues data from BigQuery and generates CSV files on GCS suitable for import into Google AutoML. The notebook then launches an AutoML job to train a model.
We chose AutoML because we wanted to focus on building a complete end to end solution rather than iterating on the model. AutoML provides a competitive baseline that we may try to improve upon in the future.
To easily view the executed notebook we convert it to html and upload it to GCS which makes it easy to serve public, static content. This allows us to use notebooks to generate rich visualizations to evaluate our model.
Model Deployment
To deploy our model we have a Tekton task that:
- Uses kpt to update our configmap with the desired value.
- Runs git to push our changes to a branch.
- Uses a wrapper around the GitHub CLI (gh) to create a PR.
The controller ensures there is only one Tekton pipeline running at a time. We configure our pipelines to always push to the same branch. This ensures we only ever open one PR to update the model because GitHub doesn’t allow multiple PRs to be created from the same branch.
Once the PR is merged Anthos Config Mesh automatically applies the Kubernetes manifests to our Kubernetes cluster.
Why Tekton
We picked Tekton because the primary challenge we faced was sequentially running a series of CLIs in various containers. Tekton is perfect for this. Importantly, all the steps in a Tekton task run on the same pod which allows data to be shared between steps using a pod volume.
Furthermore, since Tekton resources are Kubernetes resources we can adopt the same GitOps pattern and tooling to update our pipeline definitions.
The Control Loop
Finally, we needed to build a control loop that would periodically invoke our lambdas and launch our Tekton pipelines as needed. We used kubebuilder to create a simple custom controller. Our controller’s reconcile loop will call our lambda to determines whether a sync is needed and if so with what parameters. If a sync is needed the controller fires off a Tekton pipeline to perform the actual update. An example of our custom resource is illustrated below:
apiVersion: automl.cloudai.kubeflow.org/v1alpha1
kind: ModelSync
metadata:
name: modelsync-sample
namespace: label-bot-prod
spec:
failedPipelineRunsHistoryLimit: 10
needsSyncUrl: http://labelbot-diff.label-bot-prod/needsSync
parameters:
- needsSyncName: name
pipelineName: automl-model
pipelineRunTemplate:
spec:
params:
- name: automl-model
value: notavlidmodel
- name: branchName
value: auto-update
- name: fork
value: git@github.com:kubeflow/code-intelligence.git
- name: forkName
value: fork
pipelineRef:
name: update-model-pr
resources:
- name: repo
resourceSpec:
params:
- name: url
value: https://github.com/kubeflow/code-intelligence.git
- name: revision
value: master
type: git
serviceAccountName: auto-update
successfulPipelineRunsHistoryLimit: 10
The custom resource specifies the endpoint, needsSyncUrl, for the lambda that computes whether a sync is needed and a Tekton PipelineRun, pipelineRunTemplate, describing the pipeline run to create when a sync is needed. The controller takes care of the details; e.g. ensuring only 1 pipeline per resource is running at a time, garbage collecting old runs, etc… All of the heavy lifting is taken care of for us by Kubernetes and kubebuilder.
Note, for historical reasons the kind, ModelSync, and apiVersion automl.cloudai.kubeflow.org are not reflective of what the controller actually does. We plan on fixing this in the future.
Build Your Own CI/CD pipelines
Our code base is a long way from being polished, easily reusable tooling. Nonetheless it is all public and could be a useful starting point for trying to build your own pipelines.
Here are some pointers to get you started:
- Use the Dockerfile to build your own ModelSync controller
- Modify the kustomize package to use your image and deploy the controller
- Define one or more lambdas as needed for your use cases
- You can use our Lambda server as an example
- We wrote ours in go but you can use any language and web framework you like (e.g. flask)
- Define Tekton pipelines suitable for your use cases; our pipelines(linked below) might be a useful starting point
- Notebook Tekton task - Run notebook with papermill and upload to GCS
- PR Tekton Task - Tekton task to open GitHub PRs
- Define ModelSync resources for your use case; you can refer to ours as an example
- ModelSync Deploy Spec - YAML to continuously deploy label bot
- ModelSync Train Spec - YAML to continuously train our model
If you’d like to see us clean it up and include it in a future Kubeflow release please chime in on issue kubeflow/kubeflow#5167.
What’s Next
Lineage Tracking
Since we do not have an explicit DAG representing the sequence of steps in our CI/CD pipeline understanding the lineage of our models can be challenging. Fortunately, Kubeflow Metadata solves this by making it easy for each step to record information about what outputs it produced using what code and inputs. Kubeflow metadata can easily recover and plot the lineage graph. The figure below shows an example of the lineage graph from our xgboost example.
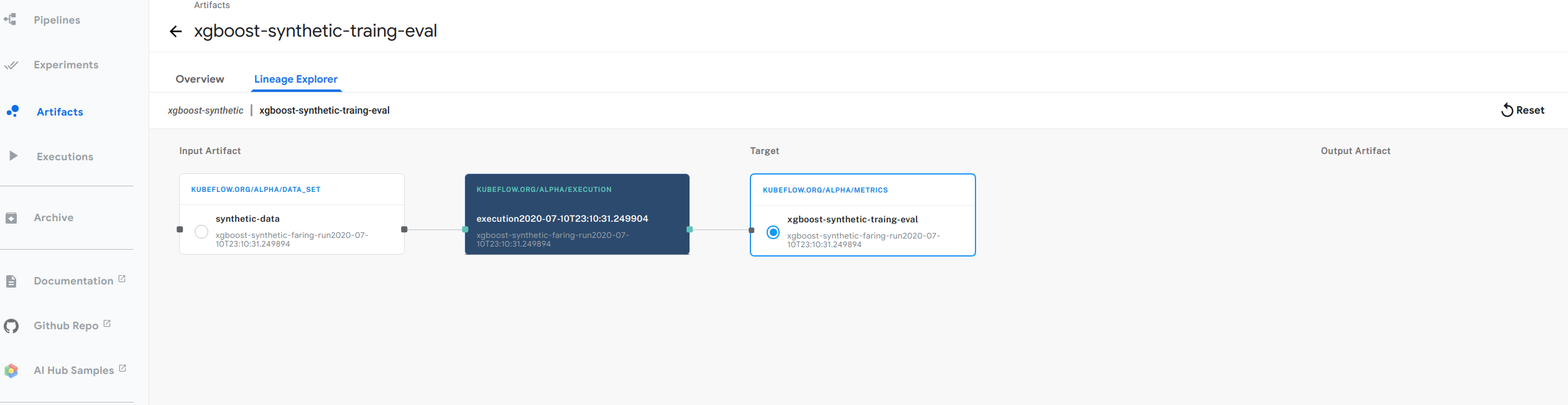
Our plan is to have our controller automatically write lineage tracking information to the metadata server so we can easily understand the lineage of what’s in production.
Conclusion

Building ML products is a team effort. In order to move a model from a proof of concept to a shipped product, data scientists and devops engineers need to collaborate. To foster this collaboration, we believe it is important to allow data scientists and devops engineers to use their preferred tools. Concretely, we wanted to support the following tools for Data Scientists, Devops Engineers, and SREs:
- Jupyter notebooks for developing models.
- GitOps for continuous integration and deployment.
- Kubernetes and managed cloud services for underlying infrastructure.
To maximize each team’s autonomy and reduce dependencies on tools, our CI/CD process follows a decentralized approach. Rather than explicitly define a DAG that connects the steps, our approach relies on a series of controllers that can be defined and administered independently. We think this maps naturally to enterprises where responsibilities might be split across teams; a data engineering team might be responsible for turning weblogs into features, a modeling team might be responsible for producing models from the features, and a deployments team might be responsible for rolling those models into production.
Further Reading
If you’d like to learn more about GitOps we suggest this guide from Weaveworks.
To learn how to build your own Kubernetes controllers the kubebuilder book walks through an E2E example.