Kubeflow SDK User Survey 2026 - Feedback, Insights and Roadmap
- Overview
- How Developers Use Kubeflow
- Key Developer Feedback
- What We’re Working on Next
- Kubeflow SDK Talks
- Join the Community
To better understand the needs of our community, the Kubeflow SDK working group recently conducted a user survey focused on the SDK and developer workflows. The goal was to gather feedback from practitioners across the ecosystem about their current tooling, common challenges, and the features they would most like to see improved.
The insights from this survey help guide the ongoing development of the Kubeflow SDK and inform priorities for future improvements in developer tooling, observability, and workflow management.
Overview
The user survey was conducted to understand how developers use Kubeflow in their day-to-day ML workflows and what improvements would most benefit the developer experience.
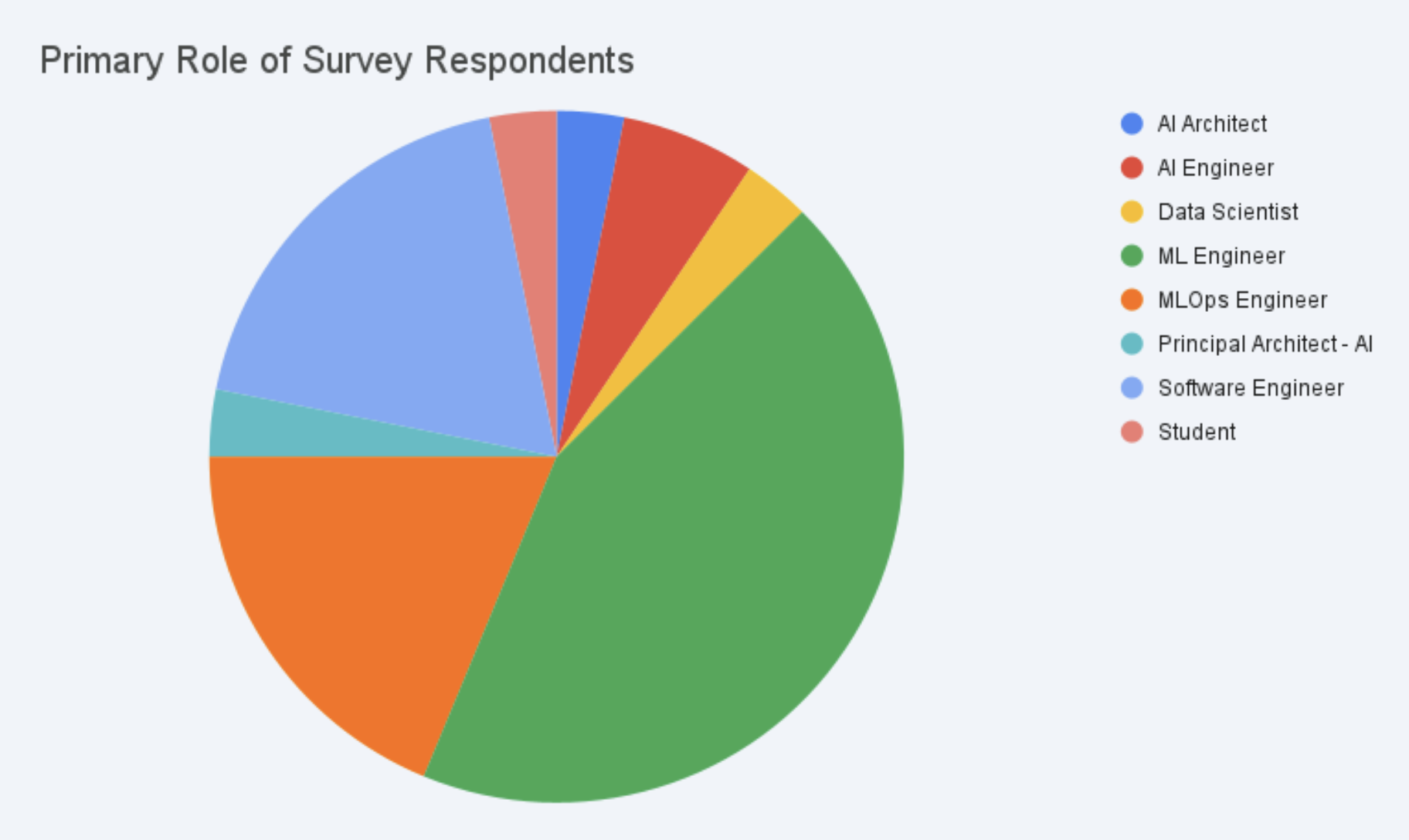
Snapshot
- Responses: 30+ practitioners from the Kubeflow ecosystem
- Audience: ML engineers, platform engineers, and AI practitioners
-
Key Focus Areas:
- Which Kubeflow components are most widely used
- Tools and frameworks used for model development
- Pain points when building and running ML workloads
- Feature priorities for improving the SDK experience
Discussion thread: https://github.com/kubeflow/sdk/discussions/155
How Developers Use Kubeflow
Survey responses show that Kubeflow is primarily used as the orchestration layer for machine learning workflows, while developers rely on familiar Python tooling for model development.
- Top Components: Kubeflow Pipelines (KFP) remains the core service used by most respondents, followed by Kubeflow Notebooks for experimentation and the Kubeflow Trainer (Training Operator) for scalable training workloads.
- Tech Stack: PyTorch is the dominant framework for model development, while VS Code and Jupyter Notebook remain the primary development environments used by practitioners.
Key Developer Feedback
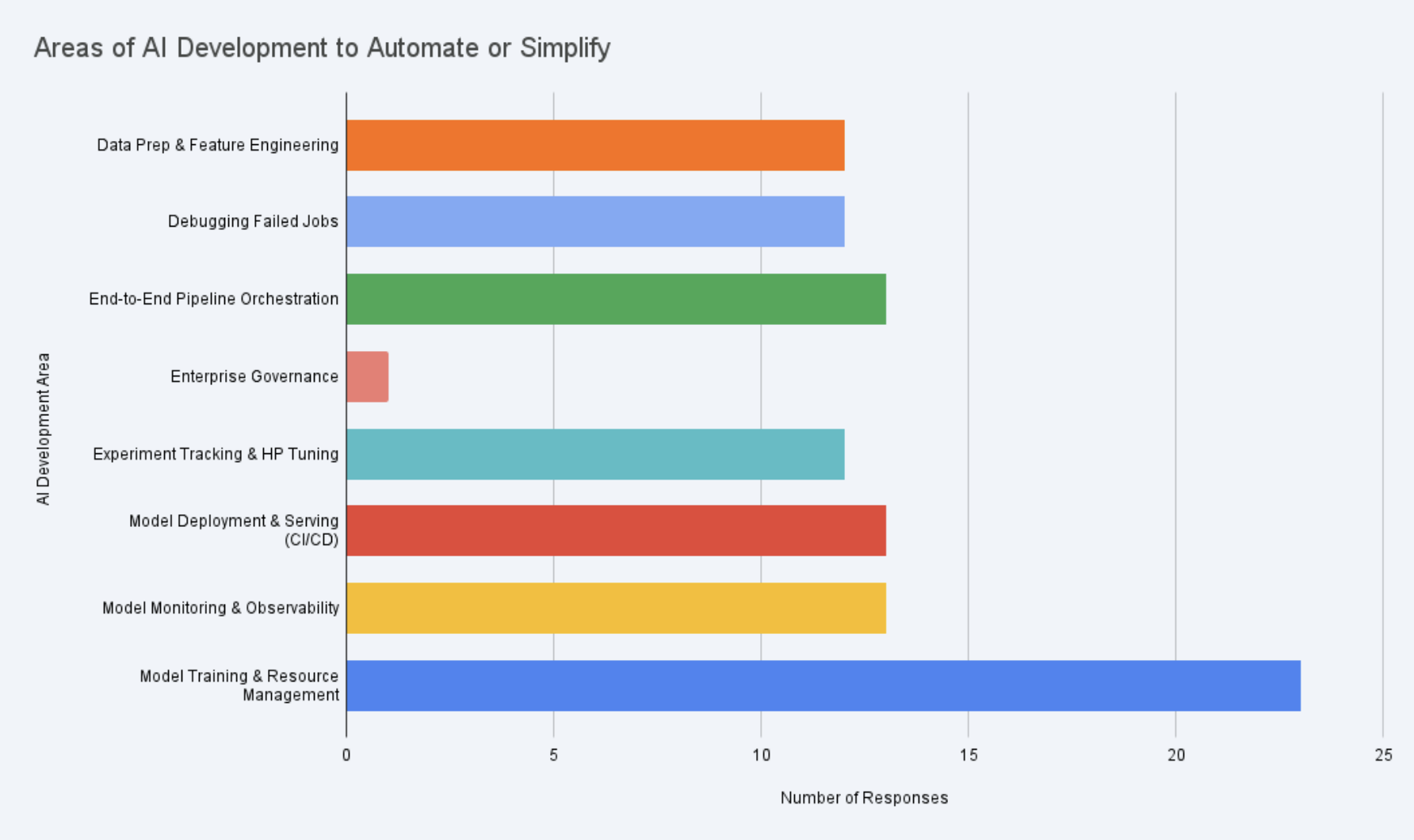
The survey responses highlighted a few recurring challenges developers face when building and running ML workloads with Kubeflow. Several patterns emerged around infrastructure complexity, debugging, and slow development cycles.
1. Training Infrastructure and Resource Management
Many respondents highlighted the operational complexity of managing distributed training workloads. Configuring GPUs, scheduling resources, and handling Kubernetes infrastructure often requires significant manual setup.
“Managing distributed training jobs and GPU resources still requires a lot of manual setup.” — Platform Engineer
2. Debugging ML Workloads Is Still Painful
Debugging distributed jobs running on Kubernetes remains a major challenge. Respondents frequently mentioned scattered logs and cryptic errors such as “OOMKilled” or networking issues during distributed training.
“When something fails, figuring out what actually went wrong takes too long.” — ML Engineer
3. The “Build → Push → Run” Cycle Slows Iteration
Several respondents pointed to the slow build → push → run workflow required to test even small changes to pipelines or training jobs.
“Every small change requires rebuild, push, and rerun — it slows down experimentation.” — AI Practitioner
4. ML Workloads Are Becoming More Complex
Some responses also highlighted the growing complexity of modern ML systems as organizations move toward larger models and more sophisticated pipelines.
“Typical examples are no longer simple models — we need better support for complex training pipelines.” — ML Engineer
What We’re Working on Next
You can follow progress and planned work in the SDK 0.4 roadmap: SDK 2026 Roadmap. We encourage the community to review the roadmap, share feedback, and contribute ideas as these features continue to evolve.
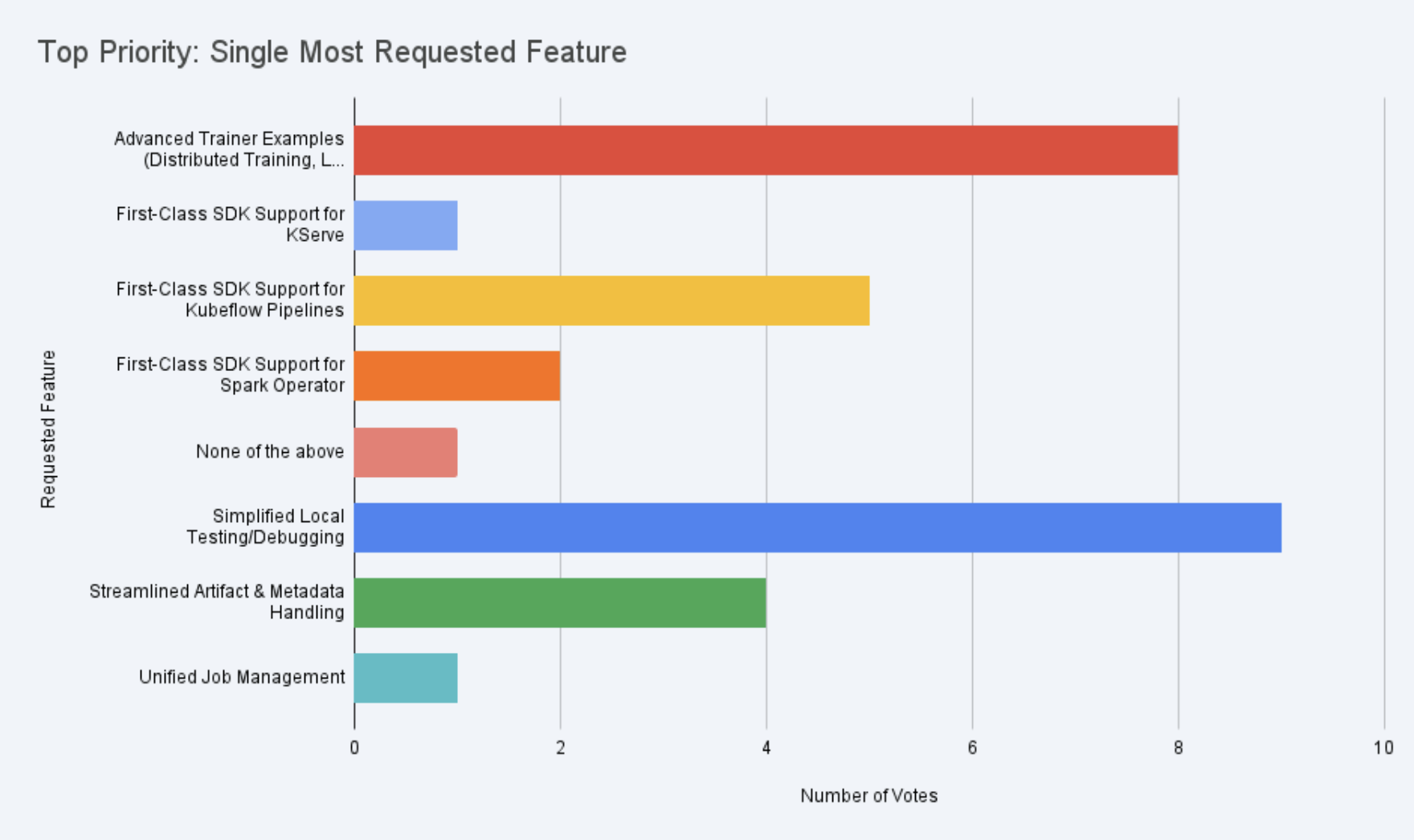
Below are a few top feedback from the survey that we are already working on.
Local Testing and Faster Iteration
The highest-rated feature in the survey was Local Testing and Debugging (4.13 / 5). Many developers highlighted the slow build → push → run workflow when testing ML jobs on a cluster.
To address this, we are working on local execution capabilities that allow developers to run and debug workloads before submitting them to Kubernetes. This includes local execution support for SDK clients such as TrainerClient and OptimizerClient, enabling faster experimentation and shorter development cycles. Check out details here: issue
Better Observability and Debugging
To improve this experience, we have planned an issue for integrating OpenTelemetry (OTel) into the SDK to provide better observability, including job progress tracking, metrics collection, and improved debugging workflows.
We are also exploring the use of an MCP server to enable AI-assisted capabilities that can help developers better understand job execution and troubleshoot failures.
Expanding Support for Modern ML Workloads
Respondents also emphasized the need for improved data flow management between pipeline components. Artifact and metadata handling ranked as the second-highest priority (3.81 / 5) in the survey.
To support more advanced ML workflows, we are expanding SDK integrations across the Kubeflow ecosystem, including tighter support for pipelines, distributed training workloads, and integrations with additional components such as ML Flow, Spark Client, model registries.
Kubeflow SDK Talks
- Streamlining ML Workflows With the Unified Kubeflow SDK
- Still Burning GPUs On Debugging? Scale AI In One Line
- Kubeflow SDK Demo - LLM Fine-Tuning with BuiltinTrainer
Join the Community
We would like to thank everyone who participated in the survey and shared their feedback. If you’re building ML platforms with Kubeflow or experimenting with the SDK, we’d love to hear your feedback.
The Kubeflow ML Experience Working Group holds open meetings and is always looking for more volunteers and users to unlock the potential of machine learning.
You can connect with the community through:
- Slack: #kubeflow-ml-experience
- Community Calendar: Kubeflow Community Calendar
- ML Experience WG Meeting Notes: Notes
Check out the Kubeflow community page to learn more.