Kubeflow v1.6 delivers support for Kubernetes v1.22 and introduces an alpha release of the Kubeflow Pipeline v2 functionality
The Kubeflow Community is excited to announce the availability of the Kubeflow v1.6 software release, which includes support for Kubernetes v1.22 and introduces an alpha release of the Kubeflow Pipeline v2 (KFP v2) functionality.
Kubeflow v1.6 also adds new hyperparameter support for the population based algorithm in Katib, and provides a combined Python SDK for PyTorch, MXNet, MPI, XGBoost in Kubeflow’s distributed Training Operator. For model serving, v1.6 has new ClusterServingRuntime and ServingRuntime CRDs, and a new Model Spec was introduced to the InferenceService Predictor Spec, which provides a new way to specify models in KServe 0.8. Additionally, v1.6 cleans up a few CVEs in the central dashboard and enables the PodDefaults webhook to pick-up new certificate updates. For the Kubernetes upgrade, the community developed and tested each Kubeflow component manifest with Kubernetes v1.22. As v1.22 introduced some breaking changes, the upgrade was a team effort, and this Kubeflow release management process will be useful in the community’s future updates of Kubernetes and other software dependencies. The software is available here.
In parallel to developing these new software features, the Kubeflow Community also completed its annual user survey. The survey generated many good user insights into requirements for Kubeflow, and you can see more on the survey results. Of the many highlights, we would like to identify the growing request for model monitoring as shown in the chart below.
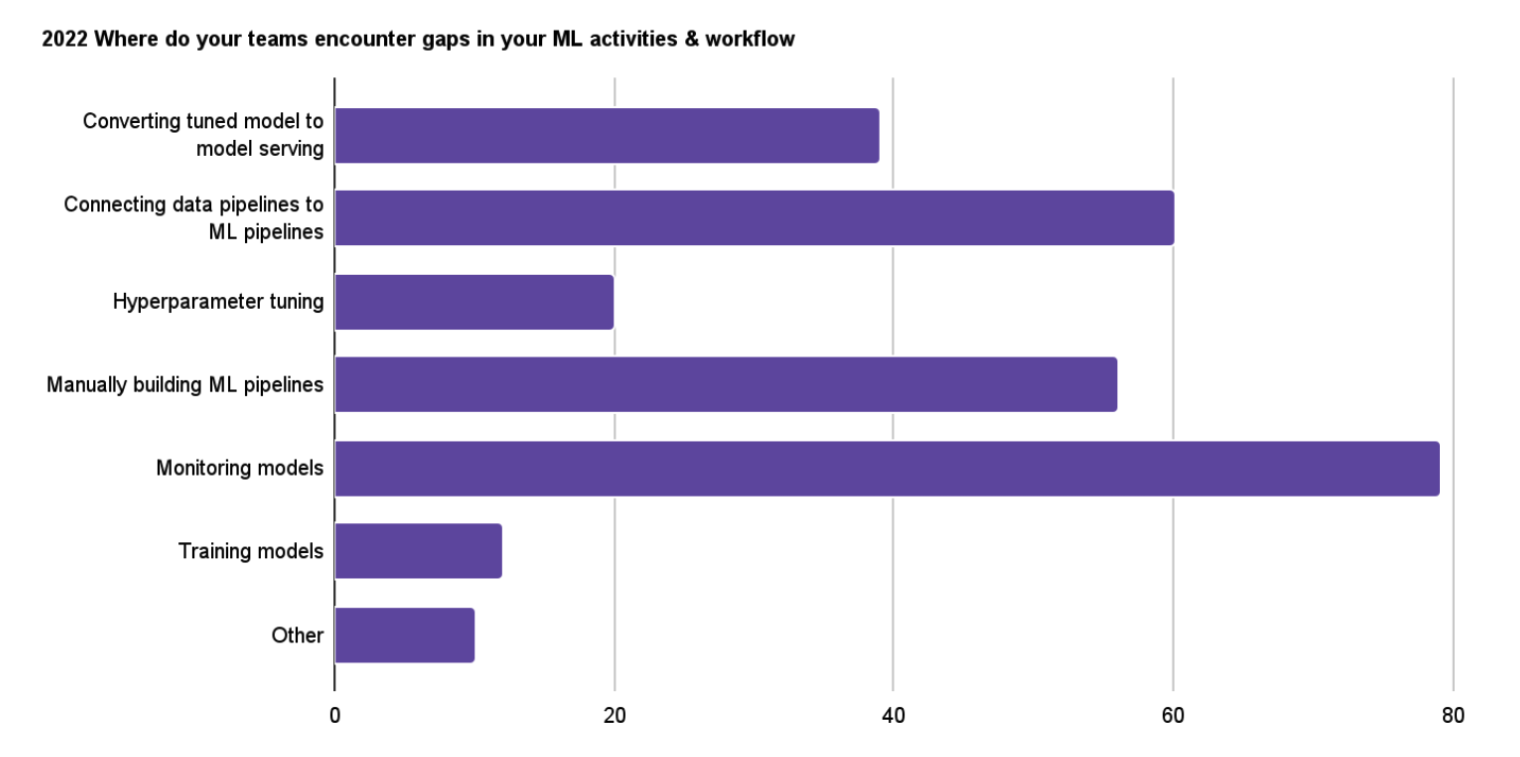
We believe the increased focus on monitoring identifies Kubeflow’s maturing user base. The Community is making efforts to explain Kubeflow’s current functionality and build into the users’ new model monitoring requirements. In addition, the user survey results and Kubeflow Working Group roadmaps will be discussed in the upcoming Kubeflow Summit. You can learn more about the Kubeflow Summit here.
To round back to the current software delivery, the following takes a deeper look at the v1.6 highlights in more detail.
Kubeflow v1.6 details
From a new feature introduction standpoint, Kubeflow v1.6 includes an experimental release of the KFP v2’s new front-end, back-end and SDK, which deliver a modern UI and DAG, first class support for metadata, and a simplified component authoring experience. This slide deck, KFP v2 Introduction, provides a good overview of v2.
The KFP v2 alpha introduces:
- An Argo-agnostic approach for creating and running pipelines
- A brand new DAG visualization, which uses the Pipeline Template and MLMD in this pipeline spec
- Streamlined Component Authoring
You can learn more about KFP v2 and the related breaking changes in these docs:
- KFP v2 Introduction
- The SDK reference
- Breaking changes including an SDK change from
kfp.v2tokfp
For those users who are still relying on the KFP v1 functionality, Kubeflow v1.6 and its KFP v2 component are fully tested and supported with the mature features in the legacy Kubeflow Pipelines v1.8 SDK. This provides the same functionality that thousands of KFP v1 users leverage in production today.
In addition to the KFP v2 alpha, Kubeflow 1.6 includes feature enhancements and operational improvements for Katib users. These include support for:
- The population based training algorithm
- Enhanced validation checks for configurations, which will save time debugging parameter misconfiguration
- Security fixes
- MetricsUnavailable Status support, which will make debugging easier
In Kubeflow v1.6, the Training Operator Working Group added these valuable enhancements:
- Python SDK for PyTorch, MXNet, MPI, XGBoost
- The Clientset (Golang) is also generated for PyTorch, MXNet, MPI, XGBoost
- Gang scheduling support for MPI
Kubeflow v1.6 has several functional and operational improvements to Kubeflow notebooks, central dashboard, webapps and controllers. The following highlights the closed PRs that were considered medium-sized or larger. You can review the full list of the closed PRs here.
- Support for K8s 1.22
- PodDefaults webhook picking up new certificates
- Show objects from all names spaces in Central Dashboard, Jupyter, Tensorboard, Volumes Mgr
- Updated the hosting container registry of images, note - this could be a breaking change for users with custom manifests
- CVE fixes for Central Dashboard
The Manifest Working Group contributed several enhancements in 1.6. These enhancements include the testing of each Kubeflow’s component manifest for:
- Compatibility with K8s 1.22
- The manifests that can be applied
- The Pods of components that can become ready
- The basic objects that can be created
For model serving, Kubeflow v1.6 incorporates the KServe v0.8.0 release, which includes these enhancements:
- ClusterServingRuntime and ServingRuntime CRDs
- A new Model Spec is introduced to the InferenceService Predictor Spec as a new way to specify models
- Support for Knative 1.0+
- gRPC for transformer to predictor network communication
- Multi-namespace support for the ModelMesh alternative backend
KServe has these breaking changes to the Python SDK:
- KFModel is renamed to Model
- KFServer is renamed to ModelServer
- KFModelRepository is renamed to ModelRepository
To learn more please see the KServe v0.8 release notes and Release blog post.
Join the community
We would like to thank everyone for their contribution to Kubeflow 1.6, especially Anna Jung for her work as the v1.6 Release Manager. The Kubeflow community is incredibly pleased to have Amazon Web Services extending their support by offering AWS promotional credits. We hope this sponsorship will enable many Kubeflow Working groups to sustainably host their testing and CI/CD infrastructure on AWS, which is essential for maintaining the community’s high development velocity. As you can see, the Kubeflow community is vibrant and diverse, solving real-world problems for organizations worldwide.
Want to help? The Kubeflow community Working Group hold open meetings and are always looking for more volunteers and users to unlock the potential of machine learning. If you’re interested in becoming a Kubeflow contributor, please feel free to check out the resources below. We look forward to working with you!
- Visit our Kubeflow website or Kubeflow GitHub Page
- Join the Kubeflow Slack channel
- Join the kubeflow-discuss mailing list
- Attend a weekly community meeting