Synthetic Data Generation with Kubeflow Pipelines
- Synthetic Data Generation - Why and How?
- Key Benefits of Using Synthetic Data
- Frameworks for Creating Synthetic Data
- The Synthetic Data Vault (SDV)
- Evaluation Criteria for Synthetic Data
- Our On-Premise Analytics Platform: ARCUS
- Needed environment to create synthetic data
- Exploring the Creation and Usefulness of Synthetic Data
- Using Synthetic Data Generators to Enable Multiple Environments without Data Transfer
- Summary
Synthetic Data Generation - Why and How?
When creating insights, decisions, and actions from data, the best results come from real data. But accessing real data often requires lengthy security and legal processes. The data may also be incomplete, biased, or too small, and during early exploration, we may not even know if it’s worth pursuing. While real data is essential for proper evaluation, gaps or limited access frequently hinder progress until the formal process is complete.
To address these challenges, synthetic data provides an alternative. It mimics real data’s statistical properties while preserving privacy and accessibility. Synthetic data generators (synthesizers) are models trained on real data to generate new datasets that follow the same statistical distributions and relationships but do not contain real records. This allows for accelerated development, improved data availability, and enhanced privacy.
Depending on the technique used, synthetic data not only mirrors statistical base properties of real data but also preserves correlations between features. These synthesizers — such as those based on Gaussian Copulas, Generative Adversarial Networks (GANs), and Variational Autoencoders (VAEs) — enable the creation of high-fidelity synthetic datasets. See more description of these techniques below.
Key Benefits of Using Synthetic Data
While the above focuses on speed of development in general, and augmentation of data to improve performance of analytical modes, there are more motivations for creating (synthetic) data:
-
Enhanced Privacy and Security
Mimics real datasets without containing sensitive or personally identifiable information, mitigating privacy risks and ensuring compliance with regulations like GDPR. -
Improved Data Availability
Enables testing and training of models without requiring extensive real-world data collection. -
Innovation and Experimentation
Allows safe experimentation with new algorithms and models without exposing sensitive data, fostering rapid prototyping in a secure environment. -
Ethical and Responsible AI Development
Ensures training data is free from biases present in real-world datasets, promoting fair and unbiased AI systems. -
Accelerated Testing and Deployment
Supports testing of new products, services, and systems in a controlled yet realistic setting, ensuring they are robust, scalable, and ready for real-world use. -
Cost Efficiency
Reduces expenses related to data collection, storage, and compliance by eliminating the need for large-scale real-world data acquisition. -
Regulatory Compliance Simplification
Helps organizations navigate complex data regulations by offering a compliant alternative to real-world datasets, easing cross-border data transfers. -
Balanced and Augmented Datasets
Supplements real-world data by balancing underrepresented classes, improving model performance, and reducing biases in AI training. -
Resilience Against Data Scarcity
Enables AI development in domains where real-world data is limited, expensive, or difficult to obtain—such as healthcare and cybersecurity—by generating high-quality alternative datasets.
To realize these benefits, we need effective tools for generating synthetic data. Different frameworks exist for this purpose, ranging from cloud-based platforms to open-source solutions. In this post, we focus on open-source synthetic data generation frameworks that provide control, flexibility, and on-premise deployment options.
Frameworks for Creating Synthetic Data
This post focuses exclusively on open source frameworks. Some data cannot be sent to the cloud, so some cloud-based synthetic data generation solutions are not always a good fit. For data already in cloud, we can use other cloud-based frameworks to generate synthetic data.
Synthesizers are motivated by multiple factors, but in this context, our focus remains on generating synthetic data for on-premise use.
So, what framework did we (initially) choose? Currently, we are using the open source version of SDV, an easy-to-use framework with a strong community and many useful features out-of-the-box (e.g. built-in evaluators, many modeling techniques). The field of synthetic data is evolving rapidly. While we do not aim to cover the latest advancements exhaustively, the use of Foundation models is certainly an area of interest.
One of the most widely used open-source libraries for synthetic data generation is Synthetic Data Vault (SDV). It provides multiple synthesizers, each tailored for different types of data and statistical properties.
The Synthetic Data Vault (SDV)
When you initialize and fit a synthesizer (like GaussianCopulaSynthesizer, CTGANSynthesizer, etc. - see below), it trains a model based on the dataset you provide. This model learns the distribution of the data, capturing the relationships and dependencies between different features in the dataset. The synthesizer doesn’t memorize individual records from the dataset. Instead, it tries to learn the underlying statistical patterns, correlations, and distributions present in the data.
Below are the (free) synthesizers provided by SDV that we evaluated on each use case. Each synthesizer does this differently:
- GaussianCopulaSynthesizer: Uses statistical copula functions to model relationships between features, ensuring accurate marginal distributions.
- CTGANSynthesizer: Uses Generative Adversarial Networks (GANs) to learn complex data distributions, particularly effective for categorical and mixed-type data.
- TVAESynthesizer: Leverages Variational Autoencoders (VAEs) to capture latent representations, useful for continuous and structured data.
- CopulaGANSynthesizer: Combines Copula-based statistical modeling with GANs to generate data with complex dependencies.
- PARSynthesizer: Uses autoregressive models to generate sequential data while preserving temporal dependencies.
There are more synthesizers, also from SDV, but not all are open source. We used the first four, when evaluating optimal synthesizer for our different use cases.
Generators - generating new data - on demand
Synthesizers are statistical and (more often) AI models trained to mimic the real data. Once developed, the resulting models are used to create as much synthetic data as you find useful for your use case. Once trained, the synthesizer uses the learned model to generate new synthetic data that follows the same statistical properties and distributions as the original dataset, without directly copying any real data points. If you need more data? Just call the generator.
Evaluation Criteria for Synthetic Data
But, how good is synthetic data, how do we evaluate it?
There are many aspects to consider when making use of synthetic data, and it is important to evaluate which synthetic data generation technique (synthesizer) is best for our specific dataset and use case.
We need to ensure a good balance between:
- Usability – How useful is the synthetic data for the intended use case?
- Fidelity – How well does the synthetic data preserve statistical properties of the real data?
- Privacy – Does the generated data ensure an acceptable level of privacy for the given use case?
For now, we are focusing only on usability and fidelity, using framework-provided measurements for fidelity and workflows described below to assess usability.
Comments on privacy and privacy preserving techniques
Ensuring privacy in synthetic data is a non-trivial problem, even if there are techniques to ensure levels of privacy, it remains an active area of research.
Privacy problems, in synthetic data?
While synthetic data enhances privacy by removing personally identifiable information, it is not inherently risk-free. Some key challenges include:
- Overfitting and Memorization: If a synthesizer is overfitted, it may generate synthetic records that closely resemble real data, leading to privacy leakage.
- Anomaly Exposure: Unique individuals or rare events in the dataset (e.g., a very wealthy individual or a rare disease) may be unintentionally replicated in synthetic data, creating a risk of re-identification.
- Re-identification Attacks: Even if synthetic data is statistically different from real data, attackers may use background knowledge to infer sensitive details about individuals.
One additional problem here is that it might be the anomalies we really are looking for. Currently we are experimenting with various differential privacy strategies, but it is still early days, and we do not focus on them in the examples below.
Our On-Premise Analytics Platform: ARCUS
ARCUS is Telia’s advanced on-premise analytics platform, designed to support a wide range of use cases. The platform provides a Kubeflow-based MLOps environment for descriptive, predictive, generative, and (ongoing) agentic AI. Fully built on open-source, ARCUS integrates a comprehensive stack of components into a unified platform - where Kubernetes is the cornerstone.
Needed environment to create synthetic data
For an efficient, automated selection of the best synthesizer, we need a number of things - from the underlying platform with GPUs and MLOps (Kubeflow).
- Kubeflow pipelines
- GPU capabilities (for performance and efficiency)
- Development (IDE) environment (for framework building and running)
- Modern data platform (MinIO, Airflow) automating the synthetic data generation datasets
Parallelism needed
In the (Kube)flows below, we run evaluations in parallel - one for respective synthesizer, followed by a comparison of usability and fidelity scores, selecting the ‘winner’.
Note: In earlier version of Kubeflow we noticed that the parallelism wasn’t acting as expected, waiting for all threads to complete before moving to next step. We had to create a temporary workaround for this, now solved in Kubeflow Pipelines 2.3.0.
Below, we briefly describe the base flow for selecting synthesizer, followed by one use case where we use the resulting data generator for ML development in cloud.
Exploring the Creation and Usefulness of Synthetic Data
This is what we want to do: we have a use case, the supporting data, and developed ML model.
- How similar is the synthetic data compared to the real data (interesting for e.g. visualization use cases)?
- How well do the ML models based on synthetic data keep up with ML models based on real data?
Validation of synthetic data techniques
- Create the synthetic data and save the best synthetic data generator. In this step similarity measures are created by the out of the box SDV framework
- Create the ML model (in our case classifier model) both on real data and the using the synthetic data. Compare the performance of both models against the same real data testset.
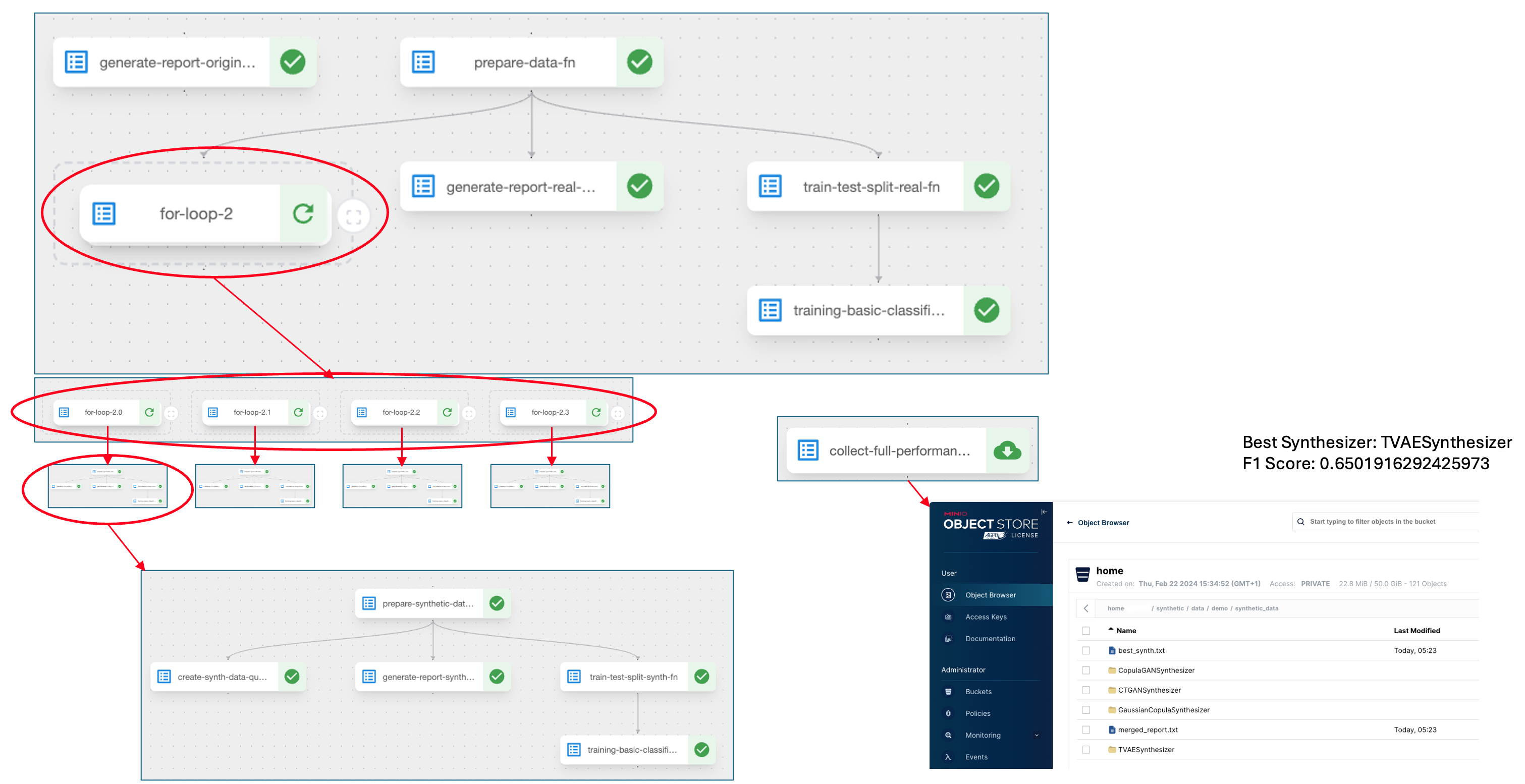
From above, we have an example where the final synthesizer is collected and saved. This step is used in the example below, exporting the resulting synthetic data generator to cloud.
Using Synthetic Data Generators to Enable Multiple Environments without Data Transfer
Below is a usecase where we need to make use of both on-premise and cloud, without moving data to cloud.
Problem statement:
- Our data cannot be moved from on-premise to cloud.
- We need extra compute power, in our public cloud environment, to create an ML model for use on-premise.
- The ML model is to be used on-premise, on new incoming data streams (that cannot be moved to cloud)
Solution:
- Create synthetic data for our on-premise environment use-cases, and - as a side product we save away the synthetic data generator (the pickled model used to create synthetic data).
- Copy the synthetic data generator to cloud
- Use the synthetic data generator in the cloud, creating synthetic data for training of an ML model
- Copy the ML model on-premise, and use it for new incoming data
- Evaluate: Compare the on-premise AI model with the model created in the cloud - against the same test data
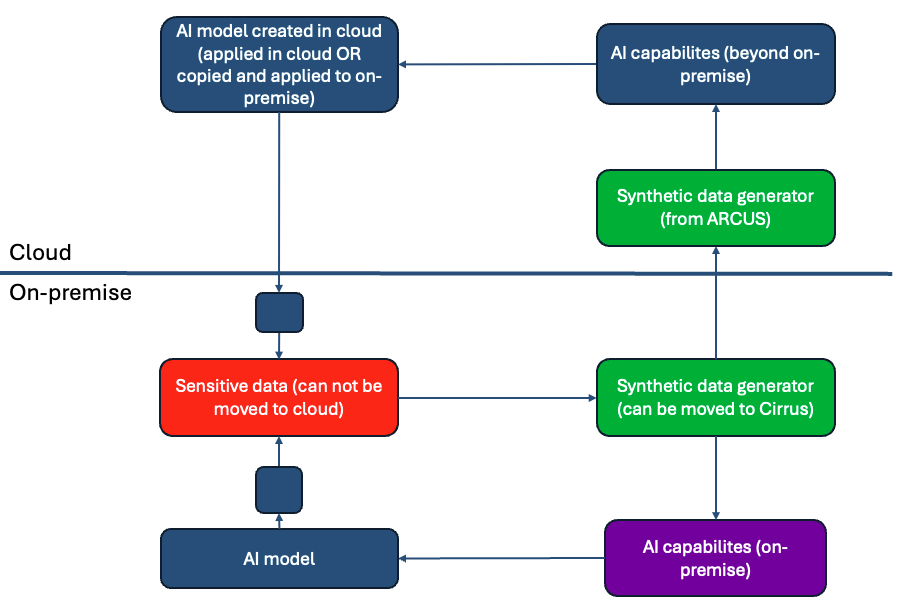
Division of work, what is done on-premise with Kubeflow, and what is done in cloud (AWS SageMaker)?
On-premise
See the above Validation of synthetic data techniques.
- Develop the model on real data – for the comparison later with the cloud model.
- Create synthetic generators, evaluate the generators, and export the best generator to AWS.
Cloud
- Use the imported synthetic generator (from on-premise)
- Create synthetic data using the synthetic data generator
- Develop the model and determine which synthetic generator is the best
- Increase the amount of synthetic data, to see if the increase of synthetic data improves model performance (not for sure it will, see below comment)
- Export model to on-premise
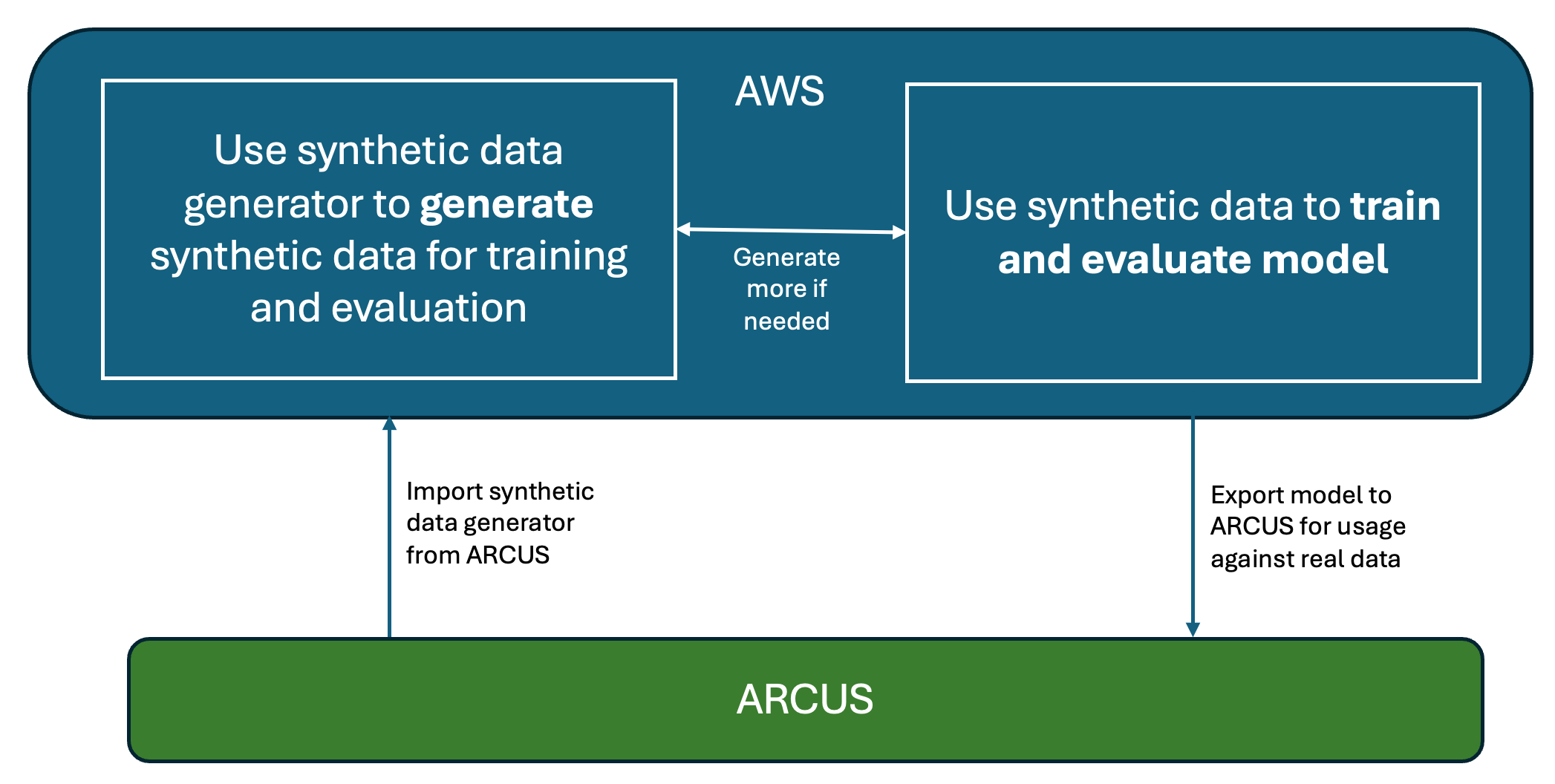
In some more detail below.
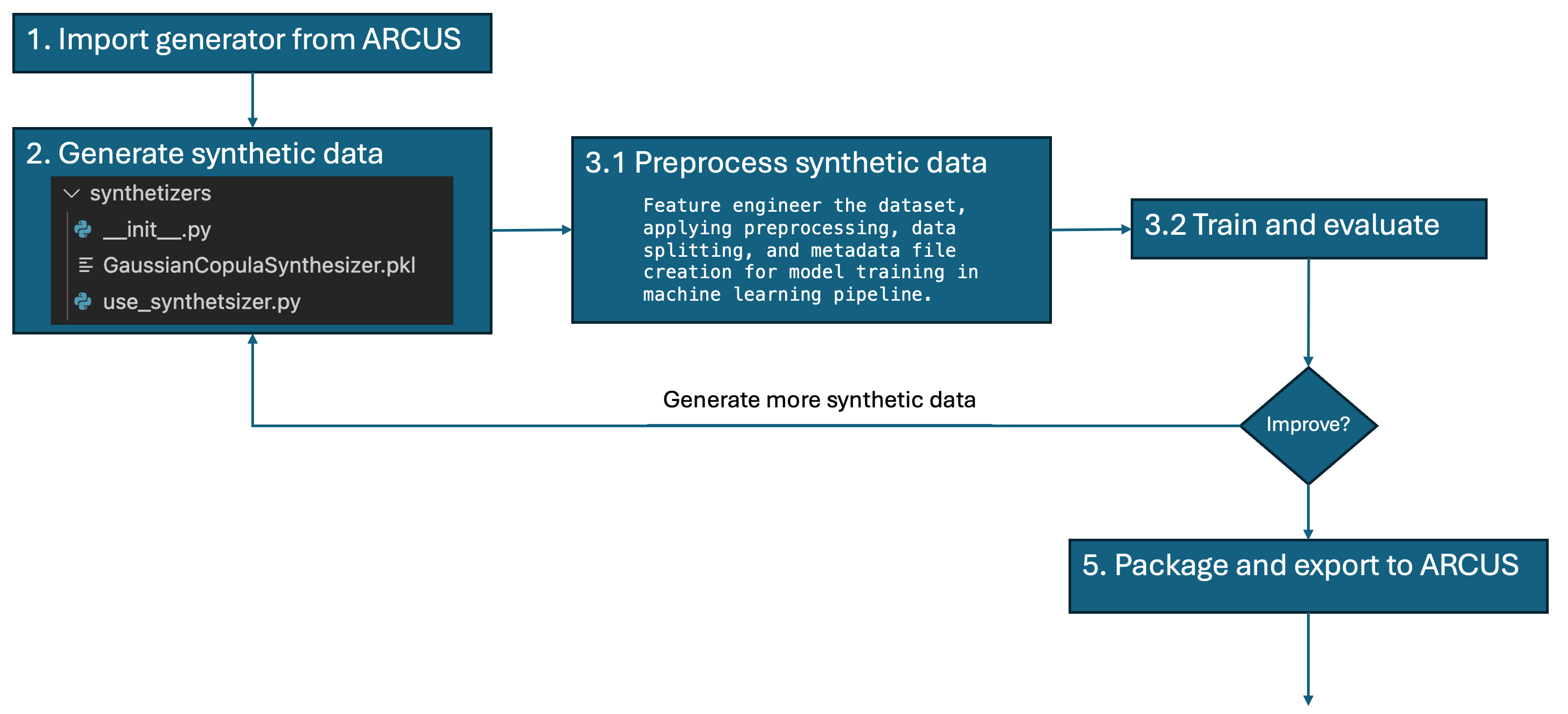
On-premise
- Compare real data model against synthetic data model – using real test data.
In the current examples we see near equivalent performance of the ML models (a few percentage points lower for models created using synthetic data). We experimented with increasing the size of the synthetic dataset, with minor improvements. Augmenting the training data is expected (not tested here) to have more effects when using deep learning algorithms.
Summary
Clearly, the above workflows would be very cumbersome to build and maintain without Kubeflow. Our solution is entirely open source, Kubernetes based, and uses Kubeflow and SDV to give us the scalability, robustness, and detailed control that is required.
The area of synthetic data generation is moving fast with the overall AI field. Reports from IBM and others, of the increased usage of synthetic data for e.g. LLM training is frequent but the application areas are much greater. We also expect more capable synthesizers and, hopefully, privacy preserving techniques to keep up with the innovation in this area. Our original main motivator was speed up in innovation and experimentation, and overall - speed to market. Often a key pain for our teams.
Looking ahead, we are exploring the development of a synthesizer catalog — ideally integrated into our overall data catalog — to enable users to rapidly experiment with ideas and get started more efficiently.