GSoC 2025: Meet Our Projects and Contributors 🚀
- Introduction
- 📚 Project Highlights
- Project 1: Kubeflow Platform Enhancements
- Project 2: KServe Models Web Application Modernization
- Project 3: Istio CNI and Ambient Mesh
- Project 4: Deploying Kubeflow with Helm Charts
- Project 5: JupyterLab Plugin for Kubeflow
- Project 6: Spark Operator with Kubeflow Notebooks
- Project 7: GPU Testing for LLM Blueprints
- Project 10: Support Volcano Scheduler in Kubeflow Trainer
- Project 12: Empowering Kubeflow Documentation with LLMs 🤖
- 🎉 Wrapping Up
- 👩💻 Want to Get Involved?
Introduction
Google Summer of Code (GSoC) 2025 has been an exciting journey for the Kubeflow community! We are very grateful for Google and the open source community members dedication and effort.🎉
This year, 9 contributors from around the world collaborated with mentors to improve different parts of the Kubeflow ecosystem — from infrastructure and CI/CD, to notebooks, ML workflows, and beyond.
In this blog, we are highlighting all the projects that were part of GSoC 2025, their goals, the impact they’ve created, and the amazing contributors behind them.
👉 You can explore the full list on our GSoC 2025 page.
📚 Project Highlights
Below are the projects from this year’s GSoC. Each section includes a short summary, contributor details, and links to project resources.
Project 1: Kubeflow Platform Enhancements
Contributor: Harshvir Potpose (@akagami-harsh) Mentors: Julius von Kohout (@juliusvonkohout)
Overview:
We need an up to date S3 storage with hard multi-tenancy and run our containers with PodSecurityStandards restricted. MinIO transitioned to the AGPLv3 license in 2021, creating significant compliance challenges for the project.
This project addressed this critical blocker by implementing SeaweedFS as a production-ready replacement for MinIO. SeaweedFS offers a more permissive Apache 2.0 license while providing superior performance characteristics and enterprise-grade security and reliability.
Key Outcomes:
- Provided S3 storage with hard multi-tenancy
- Successfully migrated to SeaweedFS as a secure replacement for MinIO and integrated it into Kubeflow Pipelines
- Eliminated MinIO’s licensing constraints by adopting SeaweedFS’s more permissive license model
- Implemented comprehensive CI tests for SeaweedFS deployment and namespace isolation functionality
- Strengthened the manifests repository’s CI pipeline and contributed to the dashboard migration efforts
- Enforcing PodSecurityStandards baseline/restricted
Resources:
Project 2: KServe Models Web Application Modernization
Contributor: (GitHub: @LogicalGuy77)
Mentors: Griffin Sullivan (@Griffin-Sullivan), Julius von Kohout (@juliusvonkohout)
Overview:
This project revived and modernized the KServe Models Web Application (Angular + Flask), the UI used to manage machine learning inference services in Kubeflow via KServe. What began as a small Node.js update evolved into a comprehensive upgrade of the frontend stack, CI/CD, testing, and feature set—bringing the app up to modern standards and making it easier for both users and contributors to work with.
Key Outcomes:
- Modernized core stack: upgraded Node.js (v16 → v23) and Angular (v12 → v14), resolving security issues and improving performance
- Migrated container images from Docker Hub to GitHub Container Registry (GHCR) to avoid rate limits and improve reliability
- Overhauled CI/CD with GitHub Actions: updated actions, added intelligent caching for pip, Docker layers, and node_modules for significantly faster builds
- Introduced Jest unit tests for core utilities (e.g., parsing Kubernetes object statuses and KServe predictor configs)
- Added Cypress end-to-end tests for critical user journeys (deploy, edit, delete) including failure handling and input validation
- Wrote comprehensive documentation to help contributors run and extend the test suites
- Shipped “Edit InferenceService YAML” directly in the UI via an integrated Monaco editor—no kubectl required
- Fixed RawDeployment-mode crash and added ModelMesh support so resources and statuses render correctly
- Added support for the latest KServe predictor runtimes, including HuggingFace
- Simplified contributor onboarding with a Makefile that automates full frontend setup in a single command
- Implemented runtime-configurable settings via a new
/api/configendpoint (e.g., Grafana DB names, URL prefixes) - Cut the v0.15.0 release of the Models Web App, consolidating months of modernization and feature work
By the Numbers:
- PRs merged: 19
- Issues closed: 8
- Lines of code changed: +22,309 / −11,628
- Frontend: Angular, TypeScript, SCSS
- Backend: Flask (Python)
- CI/CD: GitHub Actions, Docker
- Local cluster: Kubernetes (Kind) + Istio + Kubeflow
Resources:
Project 3: Istio CNI and Ambient Mesh
Contributor: Ayush Gupta (GitHub: @madmecodes)
Mentors: Julius von Kohout (@juliusvonkohout), Kimonas Sotirchos (@kimwnasptd)
Overview:
This GSoC 2025 project modernized Kubeflow’s service mesh infrastructure by implementing Istio CNI as the default configuration and pioneering Istio Ambient Mesh support. The 175-hour medium-difficulty project involved 25+ pull requests across multiple Kubeflow repositories, transitioning from traditional sidecar-based architecture to ambient mesh with ztunnel and waypoint proxies, pioneering the migration to Gateway API (HTTPRoute), implementing path-based routing for KServe model serving endpoints, and utilizing Kustomize overlay method for easy installation and configuration management.
Key Outcomes:
- Implemented Istio CNI by default with Kustomize overlay method enabling easy switching between traditional Istio and CNI configurations
- Created path-based routing for KServe multi-model serving and Gateway API (HTTPRoute) migration
- Pioneered Ambient Mesh support with ztunnel/waypoint proxies and coordinating cross-repository compatibility
Resources:
- 📄 Project Page
- ✍️ Blog Post
Project 4: Deploying Kubeflow with Helm Charts
Contributor: Kunal Dugar (@kunal-511)
Mentors: Julius von Kohout (@juliusvonkohout), Valentina Rodriguez Sosa (@varodrig), Chase Cadet (@Chasecadet)
Overview:
This project focused on creating component-based Helm charts for Kubeflow, enabling flexible and incremental deployment of ML infrastructure. Instead of requiring a full platform installation, users can now deploy specific components like Katib, Pipelines, Model Registry, and others independently with customized configurations.
Key Outcomes:
- Kubeflow AI reference platform end to end testing
- Created production-ready Helm charts for Katib, Model Registry, KServe Web App, Notebook Controller, and Kubeflow Pipelines—enabling one-command deployment of individual components
- Built automated testing infrastructure with diff tools to validate Helm charts against Kustomize manifests, ensuring accuracy and catching regressions quickly
- Enabled incremental Kubeflow adoption, reducing deployment complexity from days to hours for organizations building production ML platforms
Resources:
- 📄 Project Page
- 🧩 Kubeflow Enhancement Proposal (KEP)-831-Kubeflow-Helm-Support: Support Helm as an Alternative for Kustomize
- ✍️ Blog: My GSoC Journey: Deploying Kubeflow with Helm Charts
Project 5: JupyterLab Plugin for Kubeflow
Contributor: Amrit Kumar (@Amrit27k)
Mentors: Eder Ignatowicz (@ederign), Stefano Fioravanzo (@StefanoFioravanzo)
Overview: The project fully modernized Kubeflow Kale’s architecture, migrating the backend from KFPv1 to KFPv2 with a new Jinja2 templating system for notebook-to-pipeline conversion. The initiative also featured a complete overhaul of the JupyterLab frontend (Typescriptv5.9.2, MUIv7) and comprehensive updates to GitHub workflows, documentation, and dependencies to meet modern community standards.
Key Outcomes:
- Rebuilt the Kale backend to support the modern, future-proof Kubeflow Pipelines v2 (KFPv2) architecture, moving away from the deprecated KFPv1.
- Implemented a new Jinja2 templating system that intelligently converts annotated Jupyter notebook cells into valid KFPv2 Python DSL scripts.
- Updated the JupyterLab frontend extension using current standards (Typescript v5.9.2, Jupyterlab v4, and MUI v7), resolving hundreds of legacy compatibility issues.
- Integrated KFPv2’s robust system for better type-safe artifact handling and automated ML Metadata registration, ensuring rich lineage tracking for pipeline steps.
- Standardized the project structure, updated GitHub workflows, and implemented UI test scripts to align with community standards and ensure maintainability for future contributors.
Resources:
- 📄 Project Repo - Kubeflow Kale
- 🧩 Kubeflow Kale 2.0- Project Roadmap
- ✍️ Blog: From Notebooks to Pipelines: My GSoC’25 Journey Modernizing Kubeflow Kale with KFPv2 and Jupyterlabv4
Project 6: Spark Operator with Kubeflow Notebooks
Contributor: Fellipe Resende (@fresende)
Mentors: Shekhar Rajak (@Shekharrajak),
Luciano Resende (@lresende),
Chaoran Yu (@yuchaoran2011),
Andrey Velichkevich (@andreyvelich)
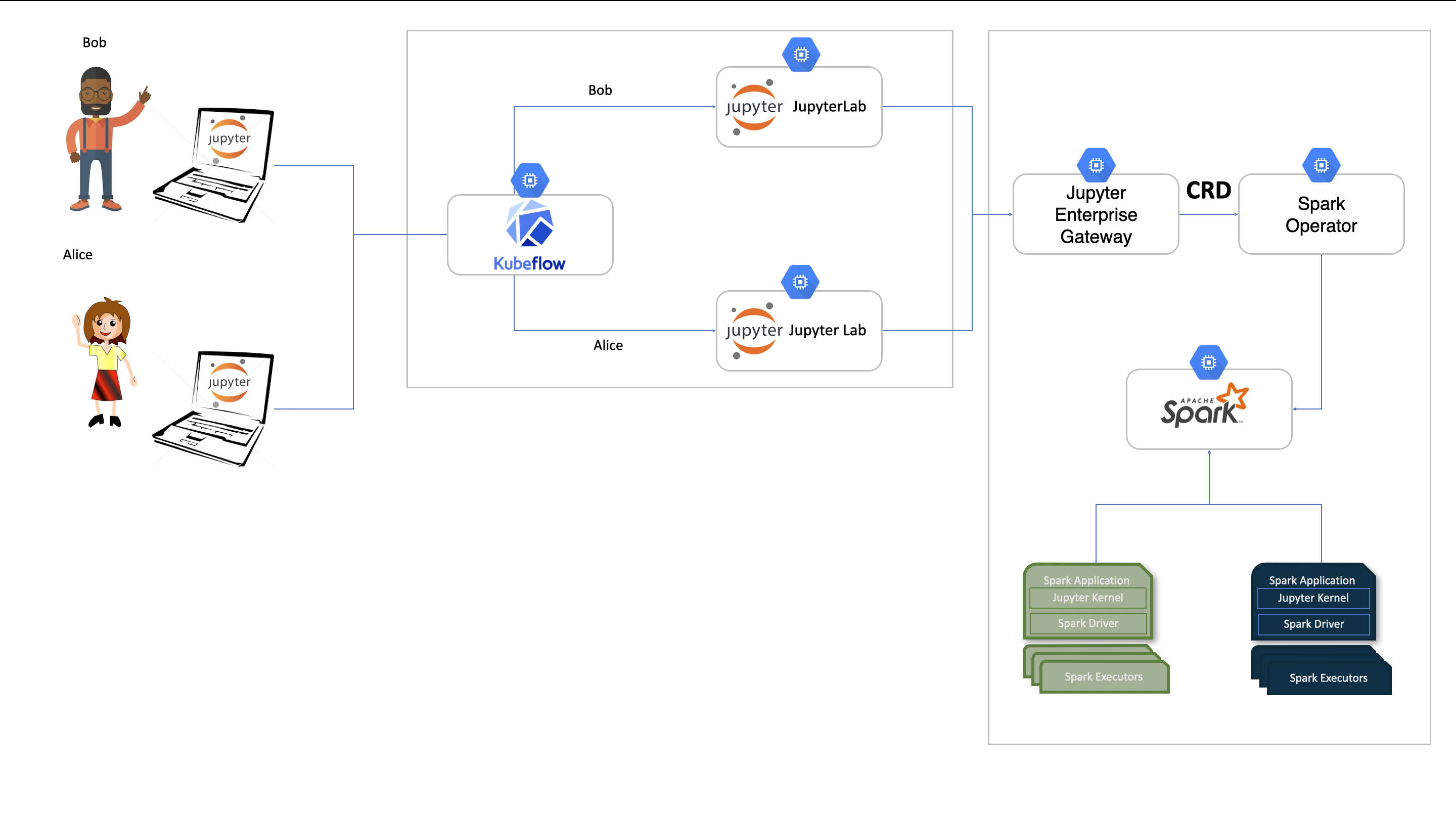
Overview: This project enables seamless PySpark execution within Kubeflow Notebooks by integrating the Spark Operator and Jupyter Enterprise Gateway. It allows data scientists to run distributed machine learning and big data workloads directly from their notebooks on Kubernetes, simplifying workflows and eliminating Spark infrastructure overhead, improving both usability and scalability within the Kubeflow ecosystem.
Key Outcomes:
-
Extended Kubeflow Notebooks to enable seamless integration with Spark via Spark Operator leveraging Jupyter Enterprise Gateway to manage the spark application lifecycle.
-
Enable data scientists and ML engineer to run distributed big-data workloads directly in Spark, from inside Kubeflow Notebooks, without manual cluster setup.
-
Provided documentation and guidance for setting up, configuring, and customizing Kubeflow Notebook environments integrated with the Spark Operator, enabling users to run scalable distributed Spark workloads directly from Jupyter-based workflows.
Resources:
- 📘 Main Documentation Page
- 🎥 Setup Demo Video
- 🐞 Debugging Demo Video
- 📄 Project Page
- 💻 Implementation Pull Request
Project 7: GPU Testing for LLM Blueprints
Contributor: Akash Jaiswal (@jaiakash)
Mentors: Andrey Velichkevich (@andreyvelich), Valentina Rodriguez Sosa(@varodrig)
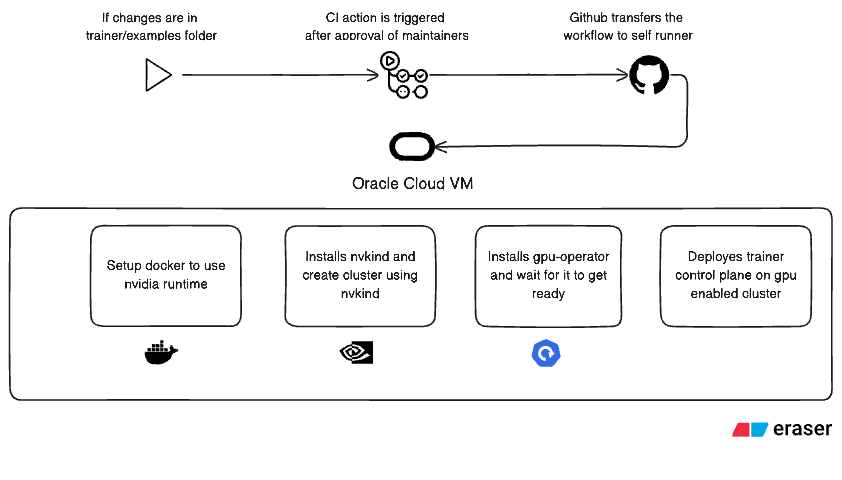
Overview:
We had a few examples in the repository that we wanted to include in our end-to-end (E2E) tests, but all of them were CPU-based. Projects like Torchtune and Qwen 2.5, for instance, require GPU resources to run — yet our existing CI setup couldn’t validate them at all because it was entirely CPU-focused.
This created a major gap: whenever someone contributed a new LLM example or modified the trainer logic, we had no automated way to verify if those changes would work in a GPU environment — the same environment where these workloads are actually deployed in production.
The goal of this project was to add CI with GPU support directly into our CI/CD workflow.
Key Outcomes:
-
Integrating GPU runners into GitHub Actions so that any pull request could automatically trigger GPU-backed E2E tests.
-
Making the setup scalable and cost-efficient — instead of maintaining expensive GPU machines 24/7, we needed an on-demand system that provisions GPU resources only when a test is triggered.
Resources:
- 📄 Project Page
- 🧩 Kubeflow Enhancement Proposal (KEP)
- ✍️ Personal Blog: Scaling GPU Testing for LLM Blueprints
Project 10: Support Volcano Scheduler in Kubeflow Trainer
Contributor: Xinmin Du (GitHub: @Doris-xm)
Mentors: Shao Wang (@Electronic-Waste), Yuchen Cheng(@rudeigerc)
Overview:
The project aims to integrate the Volcano scheduler into Kubeflow Trainer as a runtime plugin.
This will allow users to take advantage of advanced AI-specific scheduling features, such as Gang Scheduling and priority scheduling, supported by Volcano.
Key Outcomes:
- Integrate the Volcano scheduler into Trainer as a runtime plugin to support Gang Scheduling and resource management for distributed training jobs.
- Enabled AI-specific features such as priority scheduling, queue-based management, and network topology–aware scheduling.
Resources:
Project 12: Empowering Kubeflow Documentation with LLMs 🤖
Contributor: Santhosh Toorpu (GitHub: @SanthoshToorpu)
Mentors: Francisco Javier Arceo (@franciscojavierarceo), Chase Cadet (@Chasecadet)
Overview:
This project introduced an intelligent documentation assistant that uses Retrieval-Augmented Generation (RAG) and KServe-hosted LLMs to enhance the Kubeflow documentation experience. The goal was to help users find relevant, accurate answers drawn from Kubeflow docs, GitHub issues, and community discussions — all through a conversational interface on the Kubeflow website.
The system leverages Kubeflow Pipelines to automate documentation ingestion and indexing, Milvus for semantic vector search, and FastAPI with WebSockets for real-time interactions. Built on Kubernetes, the architecture follows Kubeflow’s MLOps principles end-to-end — from automated retraining and indexing to monitored LLM inference served via KServe.
Key Outcomes:
- Designed and deployed an LLM-powered Documentation Assistant using Kubeflow-native tools (KFP, KServe, Feast, Milvus).
- Implemented automated documentation indexing pipelines triggered by GitHub Actions to keep vector embeddings up-to-date.
- Developed an interactive chat interface integrated into the Kubeflow website for natural-language documentation search.
- Introduced a RAG agentic workflow with tool-calling to decide when to retrieve external documentation or use model knowledge.
- Implemented RBAC-based access control for pipelines and KServe endpoints to align with Kubeflow’s multi-user isolation standards.
- Developed a feedback loop system (“👍 / 👎”) to improve the model’s performance and documentation quality.
- Delivered a functional prototype hosted on Kubernetes, showcasing real-time semantic search across Kubeflow repositories.
Resources:
🎉 Wrapping Up
We are proud of what our GSoC 2025 contributors achieved and the impact they have made on the Kubeflow ecosystem. Their work not only strengthens existing components but also lays the foundation for future innovation in MLOps and AI infrastructure.
A huge thank you 🙏 to all contributors, mentors, and community members who made this program a success.
👩💻 Want to Get Involved?
The Kubeflow community is open to contributors of all backgrounds and skill levels. Whether you are passionate about ML infrastructure, frontend, DevOps, or documentation — there’s a place for you here.
- 💻 Visit our website and GitHub
- 💬 Join our Slack
- 🗓️ Attend the community calls
- 📩 Subscribe to the kubeflow-discuss mailing list
Let’s continue building the future of MLOps together 🚀