Elastic Training with MPI Operator and Practice
With increase in the size of dataset and deep learning models, distributed training emerges as the mainstream approach for training neural network models in industry. While it is feasible now to launch a massive distributed training job on Kubernetes with Kubeflow, advanced features like elastic workload and other cost mitigation approaches remain leashed when we talk about deep learning jobs on Kubernetes.
To address issues on cost and resource utilization, the TKE (Tencent Kubernetes Engine) AI team designs and implements Elastic Training in Kubeflow community.
Here we present how the elastic training is performed on Kubernetes. Validated with experiments under circumstances, elastic training lowers cost for distributed training on cloud.
Background
Let’s first recap training deep learning models. When we talk about ‘training’, it refers generally to iteratively optimizing parameters in a neural network model with its gradient descent. Accelerated with GPUs, the training can speed up for 10-100 times.
When manufacturers try to integrate more computational resources like GPUs into a single machine, to hold training experiments with more and more data or model parameters, the cost grows exponentially. Therefore, after initially proposed by Mu Li on OSDI’14, distributed training takes over training on a single machine when researchers play with massive dataset or large model.
For distributed training in data-parallelism, Horovod is widely adopted given its excellent support on deep learning frameworks like TensorFlow and PyTorch, communication optimization and easier programming pattern. In Horovod, all training processes are equal participants, each of which process the gradient calculation and communication.
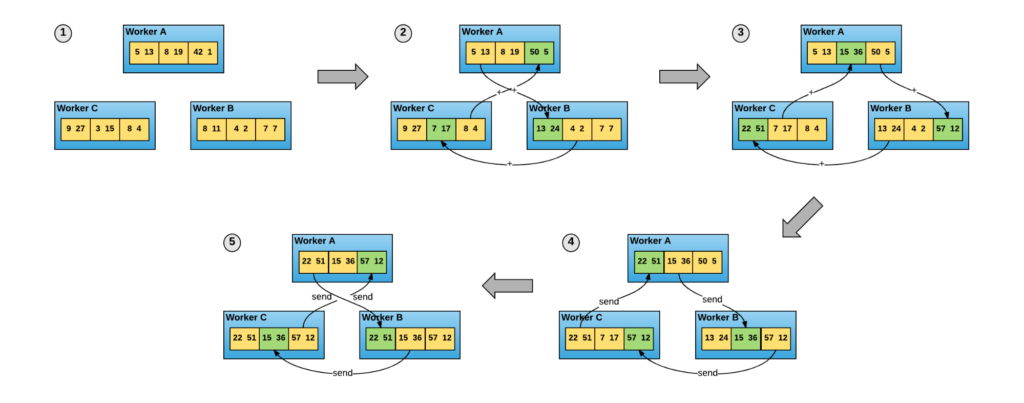
Because of significant acceleration of training speed as well as the programming pattern that are easier to understand, data-parallelism distributed training, represented by Horovod, is getting more and more attention. However, there still remain some issues:
- The cost of training on the cloud is still the hurdle. While researchers no longer face the complexity when training on cloud thanks to Kubernetes and Kubeflow, the cost of training on cloud quells some users.
- Compared with training on a single machine, multi-node distributed training accumulates the probability of training failure. The entire training experiment fails when any of its training process issues an error. This problem becomes even severer when some experiments take days or even weeks.
- When collocating training tasks with other workloads (with higher priority), the resources demand fluctuates as the request for these other workloads may change periodically. This unbalance of resources availability throws cold water on the idea of using hybrid-deployment to maximize resource utilization.
Elastic Training
Researchers and engineers proposed Elastic Training as the key to solve the puzzle.
Traditionally, the resource configuration for a distributed training job is fixed. Elastic training breaks this rule and enables users to change the number of instances participating in a distributed training job, bringing the following benefits to clusters with distributed training jobs:
- Fault Tolerance: any worker instance can fail as long as at least one is surviving.
- Resources Utilization: when the resources stress piles, the cluster is able to reduce the replicas of workloads with lower priority (distributed training workloads), releasing resource to other workloads (such as prediction service), ensuring SLA for business; after resources released from workloads, elastic training job is able to absorb these resource by scaling up workload replicas.
- Training on Cloud: there is a type of resource on the cloud that is called “spot” or “preemptible” instances; it comes with unexpected low price tags but may be retrieved after guaranteed hour expires.
Elastic training appears a perfect match to public cloud. Combined with spot instances, we cut the cost for GPUs from ¥16.21/hour to ¥1.62/hour, reducing the overall cost for the training job by nearly 70%. Under the same budget, elastic training employs more GPUs and accelerates the training speed by 5 to 10 times.
Elastic Horovod
As the major player in distributed training framework, Horovod v0.20.0 offers its solution to elastic training, Elastic Horovod. Here we quotes the architecture differences between Elastic Horovod and existing Horovod from RFC Elastic Horovod:
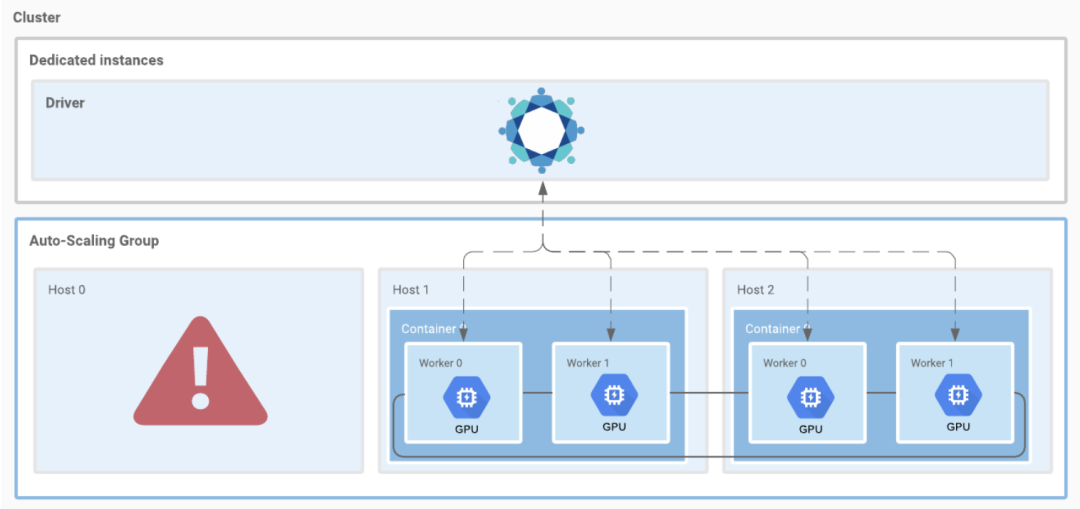
- All collective operations are coordinated within a hvd.elastic.run function.
- State is synchronized between workers before the user’s training function is executed.
- Worker failure or worker added events will result in a reset event on other workers.
- Reset events act as barriers to:
- Determine whether the job should continue based on worker exit codes.
- Blacklist failing hosts.
- Launch workers on new hosts.
- Update the rank information on existing workers.
- State is synchronized following a reset event.
When launching an elastic training job, horovodrun requires a discover_hosts.sh script to detect available hosts and slots in real time. In the following section, we refer this script as discover_hosts.sh. Nevertheless the script needs not to be named as discover_hosts.sh. An example of discover_hosts.sh can be found here.
Elastic Horovod on Kubernetes
MPI-Operator is designed to deploy Horovod jobs on Kubernetes. While the operator releases multiple versions, the general idea stays unchanged. It includes:
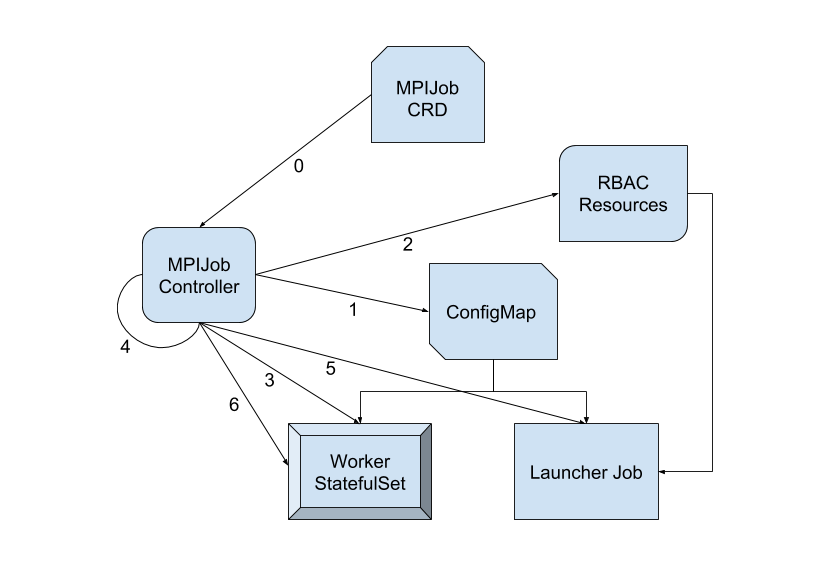
- MPIJob Controller creates a launcher pod and worker pods according to the replicas configuration in MPIJobs
- For each MPIJob, the controller creates a ConfigMap, which delivers two files:
hostfileandkubexec.sh - With all worker pods ready,
mpirunon launcher pod (granted withpod/execpermission) useskubexec.shto launch processes on worker pods
Launching an Elastic Horovod job is not feasible as there exist several incompatibilities between Elastic Horovod and MPIJob Controller. We take controller-v1 as the example:
- No built-in
discover_hosts.shavailable on launcher pod - After worker replica number is turned down, worker pods that are no longer wanted will not be deleted by the controller, leaving the size of the distributed training unchanged
- After worker replica number is turned up, the controller does not update rule in the Role binded to the launcher pod, preventing the launcher pod from creating processes on newly created pods
To address these compatibility issues, we pushed multiple pull requests regarding Horovod and MPI-Operator, including mpi-operator-pull-335 and horovod-pull-2199. As providing an MPI-Operator-specific discover_hosts.sh is most critical to the launcher pod for Elastic Horovod, we consider two scenarios for converting worker pods with a Running phase into a discover_hosts.sh script.
- A dynamic
discover_hosts.shcomposed by MPIJob controller and synchronized to the launcher pod via ConfigMap- MPIJob controller has a podLister, which can be used to list worker pods readily
- the controller filters worker pods with
status.phase == Runningand encode the result into thediscover_hosts.sh - the ConfigMap is updated when
discover_hosts.shis modified and the change will be propagated to the launcher pod by Kubernetes
- A static
discover_hosts.shusingkubectlin the launcher pod to list all running worker pods from APIServer
Scenario 2 changes the delivery image instead of the controller. However, as we cannot limit how frequently users will execute the discover_hosts.sh script, it poses a potential threat to the APIServer, especially when the count of worker pods is massive.
An fixture to scenario 2 is to replace the kubectl with a podLister process, removing extra stress from the APIServer. In this way, we install two processes in launcher pod but lack a proper mechanism to keep the podLister alive. Once the podLister dies, there leaves no elasticity for the training job.
Therefore we choose the first scenario and map the disocver_hosts.sh under /etc/mpi/. We also fixed the other compatibility issues after the worker replica configuration changes. For users choose non-elastic mode, just simply ignore /etc/mpi/discover_hosts.sh.
Concerns comes to scenario 1 as well. There is a delay between the ConfigMap and what horovodrun sees from the discover_hosts.sh in the launcher pod. This delay, on one hand, can be tweaked by cluster admin and on the other hand, can be considered as tiny compared to the training elapsed time or the time for Elastic Horovod to handle worker changes.
Demo
We present a demo to show how to operate an Elastic Horovod job with MPI Operator.
bash-5.0$ kubectl create -f ./tensorflow-mnist-elastic.yaml
mpijob.kubeflow.org/tensorflow-mnist-elastic
createdbash-5.0$ kubectl get po
NAME READY STATUS RESTARTS AGE
tensorflow-mnist-elastic-launcher 1/1 Running 0 14s
tensorflow-mnist-elastic-worker-0 1/1 Running 0 14s
tensorflow-mnist-elastic-worker-1 1/1 Running 0 14s
The job is created with two workers. After the training begins, we change MPIJob.Spec.MPIReplicaSpecs["Worker"].Replicas to 3, adding another worker. Let’s check how the discover_hosts.sh changes:
bash-5.0$ kubectl exec tensorflow-mnist-elastic-launcher -- /etc/mpi/discover_hosts.sh
tensorflow-mnist-elastic-worker-0:1
tensorflow-mnist-elastic-worker-1:1
bash-5.0$ cat ./patch_r3.yaml
spec:
mpiReplicaSpecs:
"Worker":
replicas: 3
bash-5.0$ kubectl patch mpijob tensorflow-mnist-elastic --patch "$(cat patch_r3.yaml)" --type=merge
mpijob.kubeflow.org/tensorflow-mnist-elastic patched
bash-5.0$ kubectl exec tensorflow-mnist-elastic-launcher -- /etc/mpi/discover_hosts.sh
tensorflow-mnist-elastic-worker-0:1
tensorflow-mnist-elastic-worker-1:1
tensorflow-mnist-elastic-worker-2:1
We reduce the replica count to 1, retrieving 2 worker instances.
bash-5.0$ cat ./patch_r1.yaml
spec:
mpiReplicaSpecs:
"Worker":
replicas: 1
bash-5.0$ kubectl patch mpijob tensorflow-mnist-elastic --patch "$(cat patch_r1.yaml)" --type=merge
mpijob.kubeflow.org/tensorflow-mnist-elastic patched
bash-5.0$ kubectl get po
NAME READY STATUS RESTARTS AGE
tensorflow-mnist-elastic-launcher 1/1 Running 0 4m48s
tensorflow-mnist-elastic-worker-0 1/1 Running 0 4m48s
tensorflow-mnist-elastic-worker-1 1/1 Terminating 0 4m48s
tensorflow-mnist-elastic-worker-2 1/1 Terminating 0 2m21s
The elastic training persists.
Thu Mar 11 01:53:18 2021[1]<stdout>:Step #40 Loss: 0.284265
Thu Mar 11 01:53:18 2021[0]<stdout>:Step #40 Loss: 0.259497
Thu Mar 11 01:53:18 2021[2]<stdout>:Step #40 Loss: 0.229993
Thu Mar 11 01:54:27 2021[2]<stderr>:command terminated with exit code 137
Process 2 exit with status code 137.
Thu Mar 11 01:54:27 2021[0]<stderr>:command terminated with exit code 137
Process 0 exit with status code 137.
Thu Mar 11 01:54:57 2021[1]<stderr>:[2021-03-11 01:54:57.532928: E /tmp/pip-install-2jy0u7mn/horovod/horovod/common/operations.cc:525] Horovod background loop uncaught exception: [/tmp/pip-install-2jy0u7mn/horovod/third_party/compatible_gloo/gloo/transport/tcp/pair.cc:575] Connection closed by peer [10.244.2.27]:54432
WARNING:root:blacklist failing host: tensorflow-mnist-elastic-worker-2
WARNING:root:blacklist failing host: tensorflow-mnist-elastic-worker-1
Thu Mar 11 01:54:58 2021[1]<stdout>:Step #50 Loss: 0.207741
Thu Mar 11 01:55:00 2021[1]<stdout>:Step #60 Loss: 0.119361
Thu Mar 11 01:55:02 2021[1]<stdout>:Step #70 Loss: 0.131966
As we can see, Elastic Horovod on MPI-Operator now supports tweaking worker replicas dynamically. As a future work, we aim to support Horizontal Pod Autoscaler to MPIJob as well as other features like designated worker deletion.
Conclusion
When the concept of cloud native and distributed training fuse to elastic training on Kubernetes, it lowers the cost and gives robustness and flexibility. As a team, we are working with PyTorch, Horovod and other communities to propel elastic training. We wish to further introduce our work on elasticity with PS/Worker training mode, optimization for resource and job priority and other topics on cloud native AI.