Introducing the Kubeflow SDK: A Pythonic API to Run AI Workloads at Scale
⚡ We want your feedback! Help shape the future of Kubeflow SDK by taking our quick survey.
Unified SDK Concept
Scaling AI workloads shouldn’t require deep expertise in distributed systems and container orchestration. Whether you are prototyping on local hardware or deploying to a production Kubernetes cluster, you need a unified API that abstracts infrastructure complexity while preserving flexibility. That’s exactly what the Kubeflow Python SDK delivers.
As an AI Practitioner, you’ve probably experienced this frustrating journey: you start by prototyping locally, training your model on your laptop. When you need more compute power, you have to rewrite everything for distributed training. You containerize your code, rebuild images for every small change, write Kubernetes YAMLs, wrestle with kubectl, and juggle multiple SDKs — one for training, another for hyperparameter tuning, and yet another for pipelines. Each step demands different tools, APIs, and mental models.
All this complexity slows down productivity, drains focus, and ultimately holds back AI innovation. What if there was a better way?
The Kubeflow community started the Kubeflow SDK & ML Experience Working Group (WG) in order to address these challenges. You can find more information about this WG on our YouTube playlist.
Introducing Kubeflow SDK
The SDK sits on top of the Kubeflow ecosystem as a unified interface layer. When you write Python code, the SDK translates it into the appropriate Kubernetes resources — generating CRs, handling orchestration, and managing distributed communication. You get all the power of Kubeflow and distributed AI compute without needing to understand Kubernetes.

Getting started is simple:
pip install kubeflow
from kubeflow.trainer import TrainerClient
def train_model():
import torch
model = torch.nn.Linear(10, 1)
optimizer = torch.optim.Adam(model.parameters())
# Training loop
for epoch in range(10):
# Your training logic
pass
torch.save(model.state_dict(), "model.pt")
# Create a client and train
client = TrainerClient()
client.train(train_func=train_model)
The following principles are the foundation that guide the design and implementation of the SDK:
- Unified Experience: Single SDK to interact with multiple Kubeflow projects through consistent Python APIs
- Simplified AI Workloads: Abstract away Kubernetes complexity and work effortlessly across all Kubeflow projects using familiar Python APIs
- Built for Scale: Seamlessly scale any AI workload — from local laptop to large-scale production cluster with thousands of GPUs using the same APIs.
- Rapid Iteration: Reduced friction between development and production environments
- Local Development: First-class support for local development without a Kubernetes cluster requiring only pip installation
Role in the Kubeflow Ecosystem
The SDK doesn’t replace any Kubeflow projects — it provides a unified way to use them. Kubeflow Trainer, Katib, Spark Operator, Pipelines, etc still handle the actual workload execution. The SDK makes them easier to interact with through consistent Python APIs, letting you work entirely in the language you already use for ML development.
This creates a clear separation:
- AI Practitioners use the SDK to submit jobs and manage workflows through Python, without touching YAML or Kubernetes directly
- Platform Administrators continue managing infrastructure — installing components, configuring runtimes, setting resource quotas. Nothing changes on the infrastructure side.

The Kubeflow SDK works with your existing Kubeflow deployment. If you already have Kubeflow Trainer and Katib installed, just pip install kubeflow and start using them through the unified interface. As Kubeflow evolves with new components and features, the SDK provides a stable Python layer that adapts alongside the ecosystem.
| Project | Status | Description |
|---|---|---|
| Kubeflow Trainer | Available ✅ | Train and fine-tune AI models with various frameworks |
| Kubeflow Optimizer | Available ✅ | Hyperparameter optimization |
| Kubeflow Pipelines | Planned 🚧 | Build, run, and track AI workflows |
| Kubeflow Model Registry | Planned 🚧 | Manage model artifacts, versions and ML artifacts metadata |
| Kubeflow Spark Operator | Planned 🚧 | Manage Spark applications for data processing and feature engineering |
Key Features
Unified Python Interface
The SDK provides a consistent experience across all Kubeflow components. Whether you’re training models or optimizing hyperparameters, the APIs follow the same patterns:
from kubeflow.trainer import TrainerClient
from kubeflow.optimizer import OptimizerClient
# Initialize clients
trainer = TrainerClient()
optimizer = OptimizerClient()
# List jobs
TrainerClient().list_jobs()
OptimizerClient().list_jobs()
Trainer Client
The TrainerClient provides the easiest way to run distributed training on Kubernetes, built on top of Kubeflow Trainer v2. Whether you’re training custom models with PyTorch, or fine-tuning LLMs, the client provides a Python API for submitting and monitoring training jobs at scale.
The client works with pre-configured runtimes that Platform Administrators set up. These runtimes define the container images, resource policies, and infrastructure settings. As an AI Practitioner, you reference these runtimes and focus on your training code:
from kubeflow.trainer import TrainerClient, CustomTrainer
def get_torch_dist():
"""Your PyTorch training code runs on each node."""
import os
import torch
import torch.distributed as dist
dist.init_process_group(backend="gloo")
print("PyTorch Distributed Environment")
print(f"WORLD_SIZE: {dist.get_world_size()}")
print(f"RANK: {dist.get_rank()}")
print(f"LOCAL_RANK: {os.environ['LOCAL_RANK']}")
# Create the TrainJob
job_id = TrainerClient().train(
runtime=TrainerClient().get_runtime("torch-distributed"),
trainer=CustomTrainer(
func=get_torch_dist,
num_nodes=3,
resources_per_node={
"cpu": 2,
},
),
)
# Wait for TrainJob to complete
TrainerClient().wait_for_job_status(job_id)
# Print TrainJob logs
print("\n".join(TrainerClient().get_job_logs(name=job_id)))
The TrainerClient supports CustomTrainer for your own training logic and BuiltinTrainer for pre-packaged training patterns like LLM fine-tuning.
Getting started with LLM fine-tuning is as simple as a single line. The default model, dataset, and training configurations are pre-baked into the runtime:
TrainerClient().train(
runtime=TrainerClient().get_runtime("torchtune-qwen2.5-1.5b"),
)
You can also customize every aspect of the fine-tuning process — specify your own dataset, model, LoRA configuration, and training hyperparameters:
from kubeflow.trainer import TrainerClient, BuiltinTrainer, TorchTuneConfig
from kubeflow.trainer import Initializer, HuggingFaceDatasetInitializer, HuggingFaceModelInitializer
from kubeflow.trainer import TorchTuneInstructDataset, LoraConfig, DataFormat
client = TrainerClient()
client.train(
runtime=client.get_runtime(name="torchtune-llama3.2-1b"),
initializer=Initializer(
dataset=HuggingFaceDatasetInitializer(
storage_uri="hf://tatsu-lab/alpaca/data"
),
model=HuggingFaceModelInitializer(
storage_uri="hf://meta-llama/Llama-3.2-1B-Instruct",
access_token="hf_...",
)
),
trainer=BuiltinTrainer(
config=TorchTuneConfig(
dataset_preprocess_config=TorchTuneInstructDataset(
source=DataFormat.PARQUET,
),
peft_config=LoraConfig(
apply_lora_to_mlp=True,
lora_attn_modules=["q_proj", "k_proj", "v_proj", "output_proj"],
quantize_base=True,
),
resources_per_node={
"gpu": 1,
}
)
)
)
You can mix and match — use the runtime’s default model but specify your own dataset, or keep the default dataset but customize the LoRA parameters. The Initializers download datasets and models once to shared storage, then all training pods access the data from there — reducing startup time and network usage.
For more details about Kubeflow Trainer capabilities, including gang-scheduling, fault tolerance, and MPI support, check out the Kubeflow Trainer v2 blog post.
Optimizer Client
The OptimizerClient manages hyperparameter optimization for large models of any size on Kubernetes. With consistent APIs across TrainerClient and OptimizerClient, you can easily transition from training to optimization — define your training job template once, specify which parameters to optimize, and the client orchestrates multiple trials to find the best hyperparameter configuration. This consistent API design significantly enhances the user experience during AI development.
The client launches trials in parallel according to your resource constraints, tracks metrics across experiments, and identifies optimal parameters.
First, define your training job template:
from kubeflow.trainer import TrainerClient, CustomTrainer
from kubeflow.optimizer import OptimizerClient, TrainJobTemplate, Search, Objective, TrialConfig
def train_func(learning_rate: float, batch_size: int):
"""Training function with hyperparameters."""
# Your training code here
import time
import random
for i in range(10):
time.sleep(1)
print(f"Training {i}, lr: {learning_rate}, batch_size: {batch_size}")
print(f"loss={round(random.uniform(0.77, 0.99), 2)}")
# Create a reusable template
template = TrainJobTemplate(
trainer=CustomTrainer(
func=train_func,
func_args={"learning_rate": "0.01", "batch_size": "16"},
num_nodes=2,
resources_per_node={"gpu": 1},
),
runtime=TrainerClient().get_runtime("torch-distributed"),
)
# Verify that your TrainJob is working with test hyperparameters.
TrainerClient().train(**template)
Then optimize hyperparameters with a single call:
optimizer = OptimizerClient()
job_name = optimizer.optimize(
# The same template can be used for Hyperparameter Optimisation
trial_template=template,
search_space={
"learning_rate": Search.loguniform(0.001, 0.1),
"batch_size": Search.choice([16, 32, 64, 128]),
},
trial_config=TrialConfig(
num_trials=20,
parallel_trials=4,
max_failed_trials=5,
),
)
# Verify OptimizationJob was created
optimizer.get_job(job_name)
# Wait for OptimizationJob to complete
optimizer.wait_for_job_status(job_name)
# Get the best hyperparameters and metrics from an OptimizationJob
best_results = optimizer.get_best_results(job_name)
print(best_results)
# Output:
# Result(
# parameters={'learning_rate': '0.0234', 'batch_size': '64'},
# metrics=[Metric(name='loss', min='0.78', max='0.78', latest='0.78')]
# )
# See all the trials (TrainJobs) created during optimization
job = optimizer.get_job(job_name)
print(job.trials)
This creates multiple TrainJob instances (trials) with different hyperparameter combinations, executes them in parallel based on available resources, and tracks which parameters produce the best results. Each trial is a full training job managed by Kubeflow Trainer. Using Katib UI, you can visualize your optimization with an interactive graph that shows metric performance against hyperparameter values across all trials.
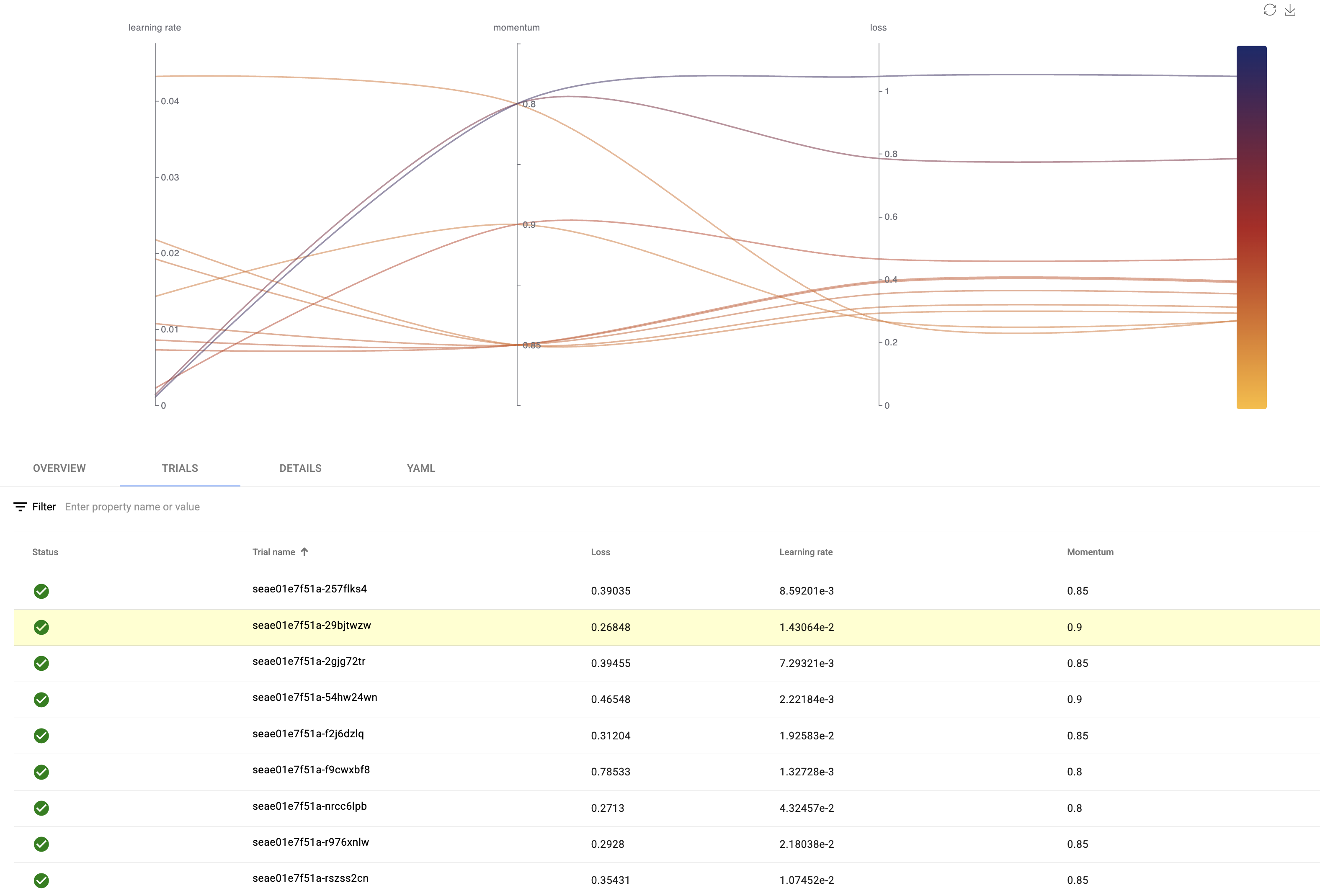
For more details about hyperparameter optimization, check out the OptimizerClient KEP.
Local Execution Mode
Local Execution Mode provides backend flexibility while maintaining full API compatibility with the Kubernetes backend, substantially reducing friction for AI practitioners when developing and iterating.
Choose the right execution environment for your stage of development:
Local Process Backend: Fastest Iteration
The Local Process Backend is your starting point for ML development - offering the fastest possible iteration cycle with zero infrastructure overhead. This backend executes your training code directly as a Python subprocess on your local machine, bypassing containers, orchestration, and network complexity entirely.
from kubeflow.trainer.backends.localprocess import LocalProcessBackendConfig
config = LocalProcessBackendConfig()
client = TrainerClient(config)
# Runs directly on your machine - no containers, no cluster
client.train(train_func=train_model)
Container Backend: Production-Like Environment
The Container Backend bridges the gap between local development and production deployment by bringing production parity to your laptop. This backend executes your training code inside containers (using Docker or Podman), ensuring that your development environment matches your production environment byte-for-byte - same dependencies, same Python version, same system libraries, same everything.
Docker Example:
from kubeflow.trainer.backends.container import ContainerBackendConfig
config = ContainerBackendConfig(
container_runtime="docker",
auto_remove=True # Clean up containers after completion
)
client = TrainerClient(config)
# Launch 2-node distributed training locally
client.train(train_func=train_model, num_nodes=2)
Podman Example:
from kubeflow.trainer.backends.container import ContainerBackendConfig
config = ContainerBackendConfig(
container_runtime="podman",
auto_remove=True
)
client = TrainerClient(config)
client.train(train_func=train_model, num_nodes=2)
Kubernetes Backend: Production Scale
The Kubernetes Backend enables Kubeflow SDK to perform reliably at production scale - enabling you to deploy the exact same training code you developed locally to a production Kubernetes cluster with massive computational resources. This backend transforms your simple client.train() call into a full-fledged distributed training job managed by Kubeflow’s Trainer, complete with fault tolerance, resource scheduling, and cluster-wide orchestration.
Kubernetes Example:
from kubeflow.trainer.backends.kubernetes import KubernetesBackendConfig
config = KubernetesBackendConfig(
namespace="ml-training",
)
client = TrainerClient(config)
# Scales to hundreds of nodes - the same code you tested locally
client.train(
train_func=train_model,
num_nodes=100,
packages_to_install=["torch", "transformers"]
)
What’s Next?
We’re just getting started. The Kubeflow SDK currently supports Trainer and Optimizer, but the vision is much bigger — a unified Python interface for the entire Cloud Native AI Lifecycle.
Here’s what’s on the horizon:
- Pipelines Integration: A PipelinesClient to build end-to-end ML workflows. Pipelines will reuse the core Kubeflow SDK primitives for training, optimization, and deployment in a single pipeline. The Kubeflow SDK will also power KFP core components
- Model Registry Integration: Seamlessly manage model artifacts and versions across the training and serving lifecycle
- Spark Operator Integration: Data processing and feature engineering through a SparkClient interface
- Documentation: Full Kubeflow SDK documentation with guides, examples, and API references
- Local Execution for Optimizer: Run hyperparameter optimization experiments locally before scaling to Kubernetes
- Workspace Snapshots: Capture your entire development environment and reproduce it in distributed training jobs
- Multi-Cluster Support: Manage training jobs across multiple Kubernetes clusters from a single SDK interface
- Distributed Data Cache: In-memory caching for large datasets via initializer SDK configuration
- Additional Built-in Trainers: Support for more fine-tuning frameworks beyond TorchTune — Unsloth, torchforge, Axolotl, LLaMA-Factory, and others
The community is driving these features forward. If you have ideas, feedback, or want to contribute, we’d love to hear from you!
Get Involved
The Kubeflow SDK is built by and for the community. We welcome contributions, feedback, and participation from everyone!
🔔 Help Shape the Future of Kubeflow SDK
We want to hear from you! Take our Kubeflow Unified SDK Survey to help us understand your biggest pain points and identify which new features will provide the most value to you and your team. Your feedback directly influences our roadmap and priorities.
Resources:
Connect with the Community:
- Join #kubeflow-ml-experience on CNCF Slack
- Attend the Kubeflow SDK and ML Experience WG meetings
- Check out good first issues to get started