Kubeflow User Survey 2022
In May 2022, the Kubeflow user survey was opened to gather community feedback. The goal of the survey was to understand the adoption of Kubeflow and to gather input on the benefits, gaps, and requirements for machine learning use cases.
The survey was comprised of 24 questions (multiple choice and freeform). It ran from May 6th to June 7th and received 151 responses. Out of the 151 responses, 91 responses provided optional feedback on how to improve Kubeflow and the Community. In the 2022 survey, we received an increased number of freeform answers, which provided additional insights into users’ needs.
Key Takeaways
- 85% of the users deploy more than one Kubeflow component
- The top 3 Kubeflow components are Pipelines (89%), Notebooks (75%), KServe (Formally KFServing) (63% - the combined result of distinct users using KServe or KFServing or both).
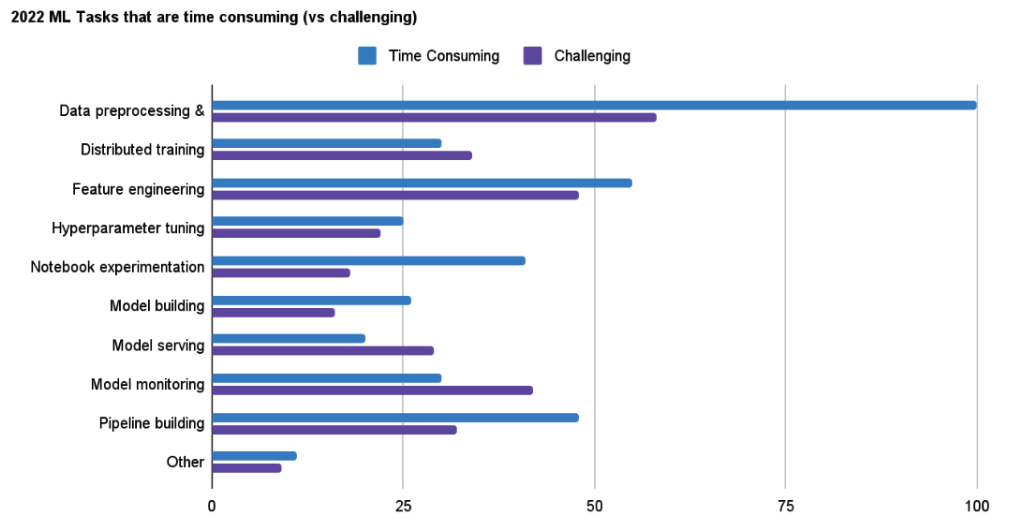
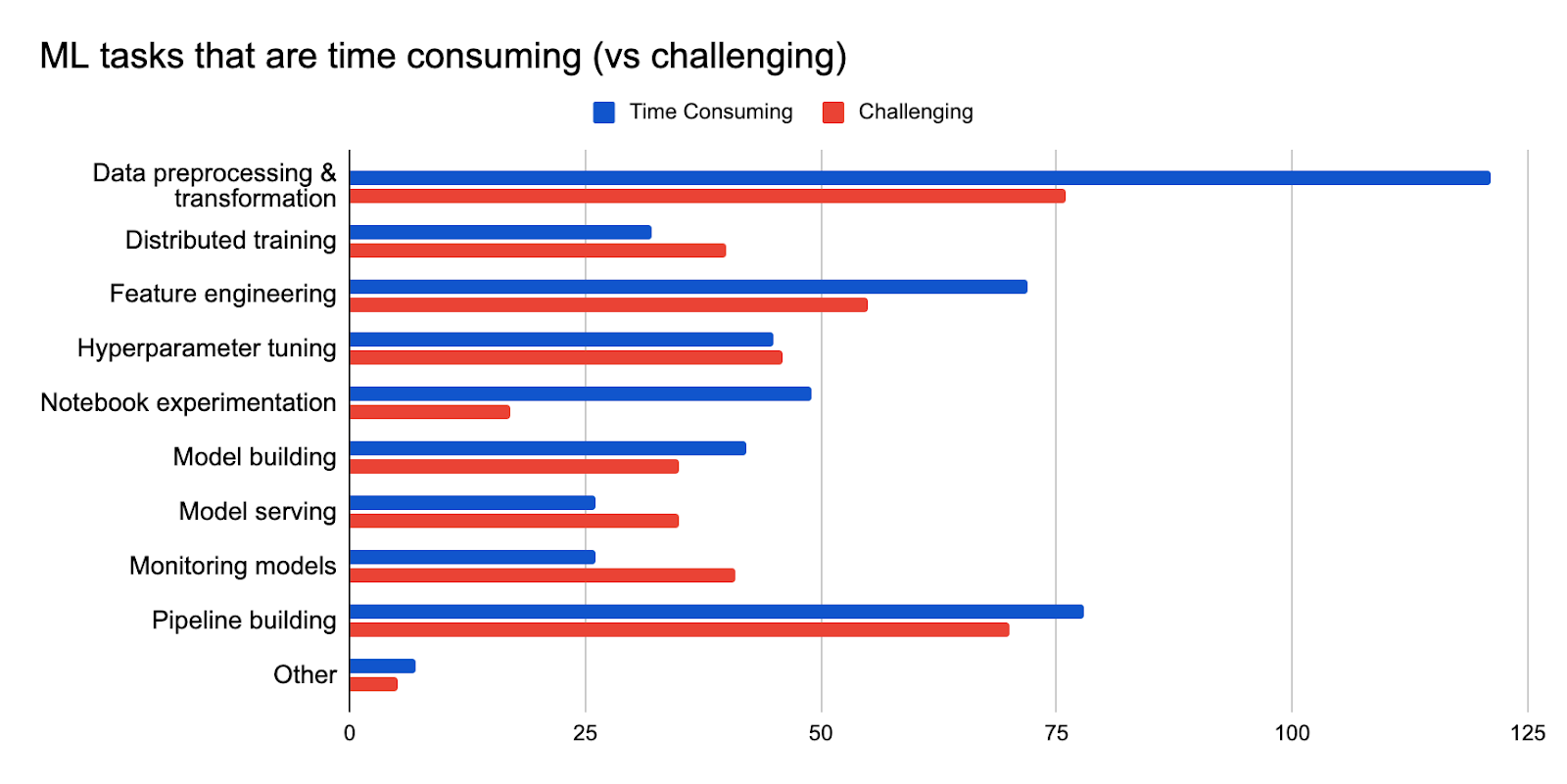
- Data preprocessing and transformations are the most challenging (44%) and time-consuming (73%) steps in the ML lifecycle
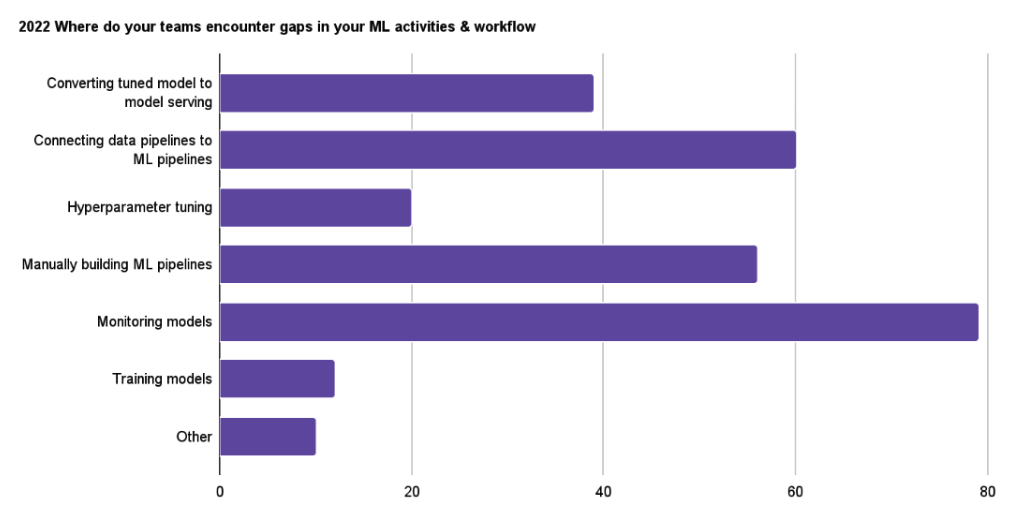
- 59% of the users identify model monitoring as the biggest gap in their ML lifecycle and 32% of the users identify model monitoring as the most challenging
- 44% of the users are running Kubeflow in production
- 90% of the users rely on the Kubeflow community for the latest tutorials
- The top 5 ML tools used by the Kubeflow users are Tensorflow (66%), Scikit-Learn (61%), PyTorch (60%), Keras (44%), and MLflow (43%)
- 47% of the users are keeping up with the latest Kubeflow 1.5 release, and 42% are running Kubeflow 1.4
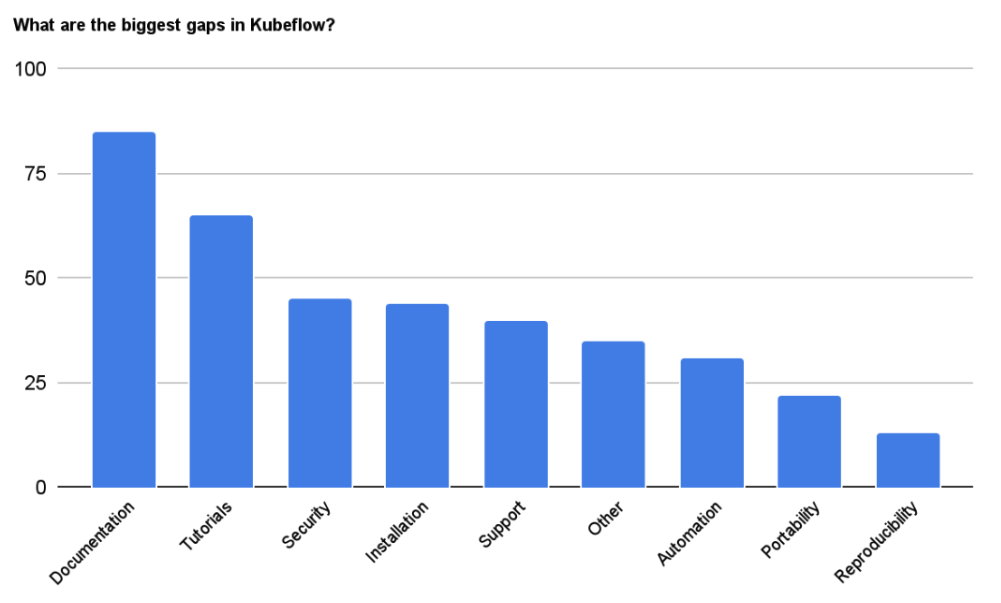
- Lack of documentation and tutorials are the biggest challenges in Kubeflow adoption
- Installation and upgrading of Kubeflow are a challenge for the users
- Users like to see security issues, especially CVEs in images addressed promptly
- Namespace isolation is the top feature request from the community
Survey Respondents
The Kubeflow user survey drew responses from 151 members of the community with experience running Kubeflow in production (44%), in the lab (23%), have experience upgrading Kubeflow cluster (18%), contributing to Kubeflow (10%), and just starting (5%).
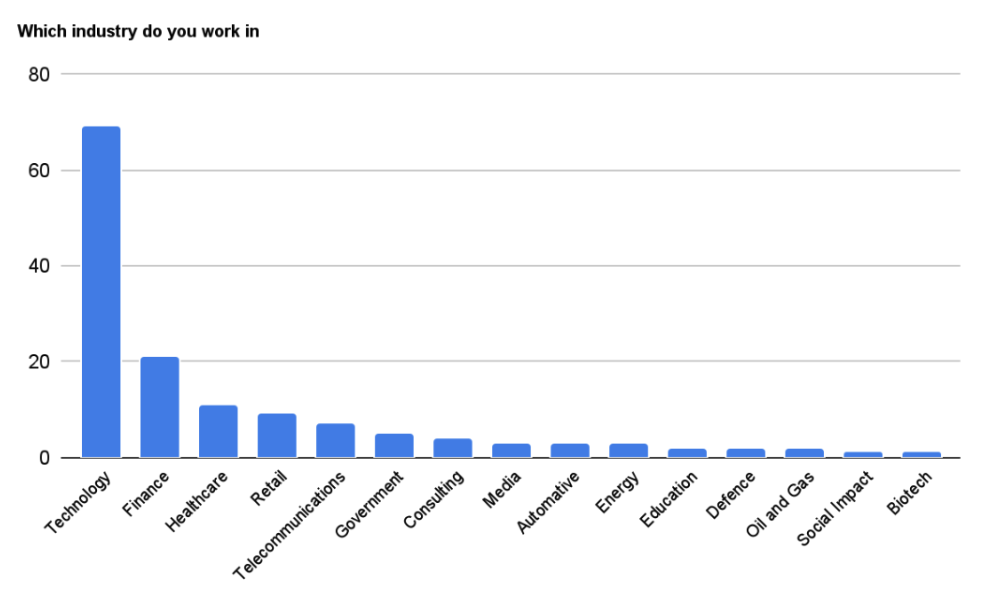
The majority of the respondents were from the Tech industry (48%), followed by Finance (15%) and Healthcare (8%).
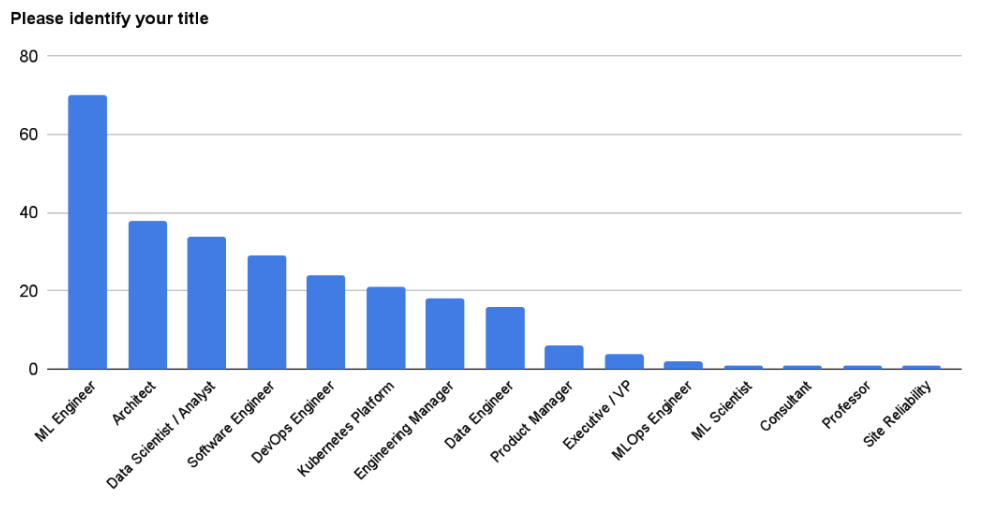
The top job titles were ML Engineers (47%), Architect (26%), and Data Scientist / Analyst (23%).
Documentation and Tutorials
Lack of documentation and tutorials are the biggest challenges in Kubeflow adoption. With new features and releases of components, the community is seeking better examples and tutorials that would help them adopt the new features.
In addition, many are still finding Kubeflow to be complicated. Users asked for additional clarity on the inner workings of Kubeflow and how to integrate with many other ML components, including other Kubeflow components.
A few of the requests from the community include
- Up-to-date versioned documentation
- A hosted playground platform to demo and learn features of Kubeflow
- Comparison between Kubeflow and other ML tools
- Tips and knowledge around running Kubeflow in production
- End-to-end tutorials on how to get the most out of all components that make up Kubeflow release
- Better example documentation from Kubeflow distributions owners
- Q&A Forum

Installation and Upgrades
One of the top three voted answers to the biggest gap in Kubeflow was installation (tied with security). In addition, > 25% of the freeform answers mentioned feedback about the installation process and/or installation tools that users would like to see supported.
Users are looking for easier installation with better support to upgrade their Kubeflow components and cluster.
Security
“… with the current state of Kubeflow, none of our customers is able to use Kubeflow without extensive modifications, as there are widely gaping security issues and tons of CVEs across all images that need to be patched before going anywhere near production.”
One of the top three voted answers to the biggest gap in Kubeflow was security (tied with installation). In addition, 16% of the freeform answers mentioned the need to improve security in Kubeflow, with top concerns being CVEs in images and user isolation.
Kubernetes Versions
“Follow k8s release cycles ahead of time, there must be support for the latest k8s versions before the oldest get officially EOL’d. Note also major changes in 1.25!”
The community raised valid concerns about Kubeflow’s lack of support for the latest Kubernetes versions. With Kubernetes 1.21 reaching its end of life on June 28th, 2022, the users found the lack of 1.22 support in the 1.5 release problematic and requested Kubeflow to keep up with the release of its dependencies.
Namespace Isolation
About 15% of the free-from responses contained the word “namespace” in relation to resource isolation that users like to see supported by Kubeflow. Many users are seeking namespaced isolation across various Kubeflow resources, which include pipelines, experiments, artifacts, and metadata.
From all the list of features requested in the survey, namespace isolation is the top request from the community.
Comparison to 2021 User Survey
Challenges with Monitoring
In both 2021 and 2022, Kubeflow users identified that data preprocessing and transformation are the most time-consuming and challenging steps in the machine learning lifecycle. While the top answers stayed the same, there were big changes to the follow-up rankings for the most challenging question.
In 2021, the top 5 challenges were data preprocessing and transformation, pipeline building, feature engineering, hyperparameter tuning, and distributed training.
In 2022, the top 5 challenges were data preprocessing and transformation, feature engineering, model monitoring, distributed training, and pipeline building. The biggest difference from last year is the change in ranking for hyperparameter tuning and seeing model monitoring moving up in the ranks.
As users find model monitoring one of the challenges in the machine learning lifecycle, it has also been identified as the biggest gap in users’ ML activities.
In 2021, the biggest gap was identified as connecting data pipelines to ML pipelines. In 2022, the biggest gap was identified as model monitoring. While the top three answers haven’t changed, data shows that monitoring is at the top of the mind of users as they find it to be most challenging and where the biggest gaps exist.
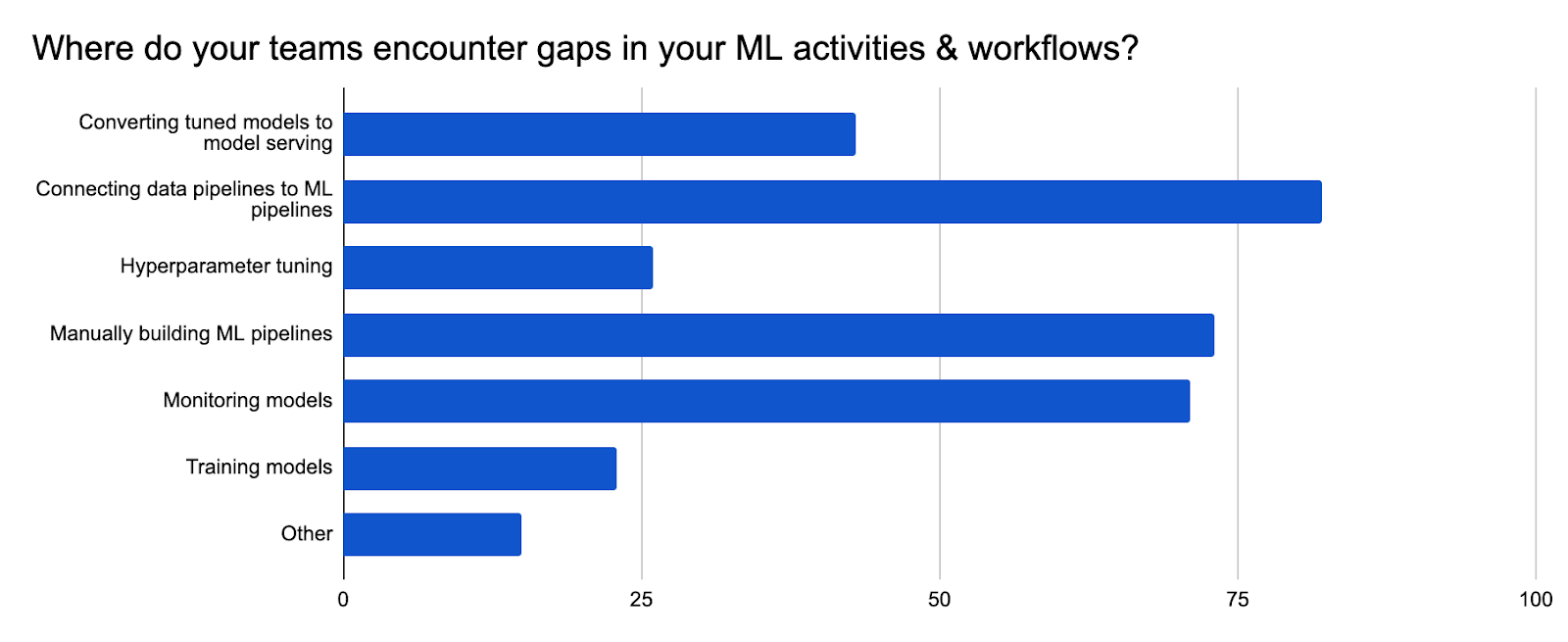
Full Survey Results
Full survey results can be found in the initial survey results and in the summary of the free-from answers.
What’s Next?
Survey results will be discussed with the Kubeflow community during the Kubeflow summit in October. More details about the summit will be shared via the kubeflow-discuss mailing list. Join the mailing list to keep up to date with Kubeflow summit news.
Join the Community
We would like to thank everyone for their participation in the survey. As you can see from the survey results, the Kubeflow Community is vibrant and diverse, solving real-world problems for organizations worldwide.
Want to help? The Kubeflow Community Working Groups hold open meetings and are always looking for more volunteers and users to unlock the potential of machine learning. If you’re interested in becoming a Kubeflow contributor, please feel free to check out the resources below. We look forward to working with you!
- Visit our Kubeflow website or Kubeflow GitHub Page
- Join the Kubeflow Slack workspace
- Join the kubeflow-discuss mailing list
- Attend a weekly community meeting