Optimizing RAG Pipelines with Katib: Hyperparameter Tuning for Better Retrieval & Generation
Leveraging Katib for efficient RAG optimization.
Introduction
As artificial intelligence and machine learning models become more sophisticated, optimising their performance remains a critical challenge. Kubeflow provides a robust component, Katib, designed for hyperparameter optimization and neural architecture search. As a part of the Kubeflow ecosystem, Katib enables scalable, automated tuning of underlying machine learning models, reducing the manual effort required for parameter selection while improving model performance across diverse ML workflows.
With Retrieval-Augmented Generation (RAG) becoming an increasingly popular approach for improving search and retrieval quality, optimizing its parameters is essential to achieving high-quality results. RAG pipelines involve multiple hyperparameters that influence retrieval accuracy, hallucination reduction, and language generation quality. In this blog, we will explore how Katib can be leveraged to fine-tune a RAG pipeline, ensuring optimal performance by systematically adjusting key hyperparameters.
Let’s Get Started!
STEP 1: Setup
Since compute resources are scarcer than a perfectly labeled dataset :), we’ll use a lightweight Kind cluster (Kubernetes in Docker) cluster to run this example locally. Rest assured, this setup can seamlessly scale to larger clusters by increasing the dataset size and the number of hyperparameters to tune.
To get started, we’ll first install the Katib control plane in our cluster by following the steps outlined in the documentation.
STEP 2: Implementing RAG pipeline
In this implementation, we use a retriever model, which encodes queries and documents into vector representations to find the most relevant matches, to fetch relevant documents based on a query and a generator model to produce coherent text responses.
Implementation Details:
- Retriever: Sentence Transformer & FAISS (Facebook AI Similarity Search) Index
- A SentenceTransformer model (paraphrase-MiniLM-L6-v2) encodes predefined documents into vector representations.
- FAISS is used to index these document embeddings and perform efficient similarity searches to retrieve the most relevant documents.
- Generator: Pre-trained GPT-2 Model
- A Hugging Face GPT-2 text generation pipeline (which can be replaced with any other model) is used to generate responses based on the retrieved documents. I chose GPT-2 for this example as it is lightweight enough to run on my local machine while still generating coherent responses.
- Query Processing & Response Generation
- When a query is submitted, the retriever encodes it and searches the FAISS index for the top-k most similar documents.
- These retrieved documents are concatenated to form the input context, which is then passed to the GPT-2 model to generate a response.
- Evaluation: BLEU (Bilingual Evaluation Understudy) Score Calculation
- To assess the quality of generated responses, we use the BLEU score, a popular metric for evaluating text generation.
- The evaluate function takes a query, retrieves documents, generates a response, and compares it against a ground-truth reference to compute a BLEU score with smoothing functions from the nltk library.
To run Katib, we will use the Katib SDK, which provides a programmatic interface for defining and running hyperparameter tuning experiments in Kubeflow.
Katib requires an objective function, which:
- Defines what we want to optimize (e.g., BLEU score for text generation quality).
- Executes the RAG pipeline with different hyperparameter values.
- Returns an evaluation metric so Katib can compare different hyperparameter configurations.
def objective(parameters):
# Import dependencies inside the function (required for Katib)
import numpy as np
import faiss
from sentence_transformers import SentenceTransformer
from transformers import pipeline
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction
# Function to fetch documents (Modify as needed)
def fetch_documents():
"""Returns a predefined list of documents or loads them from a file."""
return [
...
]
# OR, to load from a file:
# with open("/path/to/documents.json", "r") as f:
# return json.load(f)
# Define the RAG pipeline within the function
def rag_pipeline_execute(query, top_k, temperature):
"""Retrieves relevant documents and generates a response using GPT-2."""
# Initialize retriever
retriever_model = SentenceTransformer("paraphrase-MiniLM-L6-v2")
# Sample documents
documents = fetch_documents()
# Encode documents
doc_embeddings = retriever_model.encode(documents)
index = faiss.IndexFlatL2(doc_embeddings.shape[1])
index.add(np.array(doc_embeddings))
# Encode query and retrieve top-k documents
query_embedding = retriever_model.encode([query])
distances, indices = index.search(query_embedding, top_k)
retrieved_docs = [documents[i] for i in indices[0]]
# Generate response using GPT-2
generator = pipeline("text-generation", model="gpt2", tokenizer="gpt2")
context = " ".join(retrieved_docs)
generated = generator(context, max_length=50, temperature=temperature, num_return_sequences=1)
return generated[0]["generated_text"]
# TODO: Provide queries and ground truth directly here or load them dynamically from a file/external volume.
query = "" # Example: "Tell me about the Eiffel Tower."
ground_truth = "" # Example: "The Eiffel Tower is a famous landmark in Paris."
# Extract hyperparameters
top_k = int(parameters["top_k"])
temperature = float(parameters["temperature"])
# Generate response
response = rag_pipeline_execute(query, top_k, temperature)
# Compute BLEU score
reference = [ground_truth.split()] # Tokenized reference
candidate = response.split() # Tokenized candidate response
smoothie = SmoothingFunction().method1
bleu_score = sentence_bleu(reference, candidate, smoothing_function=smoothie)
# Print BLEU score in Katib-compatible format
print(f"BLEU={bleu_score}")
Note: Make sure to return the result in the format of <parameter>=<value>
for Katib’s metrics collector to be able to utilize it. More ways to configure
the output are available in Katib Metrics
Collector guide.
STEP 3: Run a Katib Experiment
Once our pipeline is encapsulated within the objective function, we can configure Katib to optimize the BLEU score by
tuning the hyperparameters:
-
top_k: The number of documents retrieved (eg. between 10 and 20). -
temperature: The randomness of text generation (eg. between 0.5 and 1.0).
Define hyperparameter search space
parameters = {
"top_k": katib.search.int(min=10, max=20),
"temperature": katib.search.double(min=0.5, max=1.0, step=0.1)
}
Let’s submit the experiment! We’ll use the tune API that will run multiple trials to find the optimal top_k
and temperature values for our RAG pipeline.
katib_client = katib.KatibClient(namespace="kubeflow")
name = "rag-tuning-experiment"
katib_client.tune(
name=name,
objective=objective,
parameters=parameters,
algorithm_name="grid", # Grid search for hyperparameter tuning
objective_metric_name="BLEU",
objective_type="maximize",
objective_goal=0.8,
max_trial_count=10, # Run up to 10 trials
parallel_trial_count=2, # Run 2 trials in parallel
resources_per_trial={"cpu": "1", "memory": "2Gi"},
base_image="python:3.10-slim",
packages_to_install=[
"transformers==4.36.0",
"sentence-transformers==2.2.2",
"faiss-cpu==1.7.4",
"numpy==1.23.5",
"huggingface_hub==0.20.0",
"nltk==3.9.1"
]
)
Once the experiment is submitted, we can see output indicating that Katib has started the trials:
Experiment Trials status: 0 Trials, 0 Pending Trials, 0 Running Trials, 0 Succeeded Trials, 0 Failed Trials, 0 EarlyStopped Trials, 0 MetricsUnavailable Trials
Current Optimal Trial:
{'best_trial_name': None,
'observation': {'metrics': None},
'parameter_assignments': None}
Experiment conditions:
[{'last_transition_time': datetime.datetime(2025, 3, 13, 19, 40, 32, tzinfo=tzutc()),
'last_update_time': datetime.datetime(2025, 3, 13, 19, 40, 32, tzinfo=tzutc()),
'message': 'Experiment is created',
'reason': 'ExperimentCreated',
'status': 'True',
'type': 'Created'}]
Waiting for Experiment: kubeflow/rag-tuning-experiment to reach Succeeded condition
.....
Experiment Trials status: 9 Trials, 0 Pending Trials, 2 Running Trials, 7 Succeeded Trials, 0 Failed Trials, 0 EarlyStopped Trials, 0 MetricsUnavailable Trials
Current Optimal Trial:
{'best_trial_name': 'rag-tuning-experiment-66tmh9g7',
'observation': {'metrics': [{'latest': '0.047040418725887996',
'max': '0.047040418725887996',
'min': '0.047040418725887996',
'name': 'BLEU'}]},
'parameter_assignments': [{'name': 'top_k', 'value': '10'},
{'name': 'temperature', 'value': '0.6'}]}
Experiment conditions:
[{'last_transition_time': datetime.datetime(2025, 3, 13, 19, 40, 32, tzinfo=tzutc()),
'last_update_time': datetime.datetime(2025, 3, 13, 19, 40, 32, tzinfo=tzutc()),
'message': 'Experiment is created',
'reason': 'ExperimentCreated',
'status': 'True',
'type': 'Created'}, {'last_transition_time': datetime.datetime(2025, 3, 13, 19, 40, 52, tzinfo=tzutc()),
'last_update_time': datetime.datetime(2025, 3, 13, 19, 40, 52, tzinfo=tzutc()),
'message': 'Experiment is running',
'reason': 'ExperimentRunning',
'status': 'True',
'type': 'Running'}]
Waiting for Experiment: kubeflow/rag-tuning-experiment to reach Succeeded condition
We can also see the experiments and trials being run to search for the optimized parameter:
kubectl get experiments.kubeflow.org -n kubeflow
NAME TYPE STATUS AGE
rag-tuning-experiment Running True 10m
kubectl get trials --all-namespaces
NAMESPACE NAME TYPE STATUS AGE
kubeflow rag-tuning-experiment-7wskq9b9 Running True 10m
kubeflow rag-tuning-experiment-cll6bt4z Running True 10m
kubeflow rag-tuning-experiment-hzxrzq2t Running True 10m
The list of completed trials and their results will be shown in the UI like below. Steps to access Katib UI are available in the documentation:
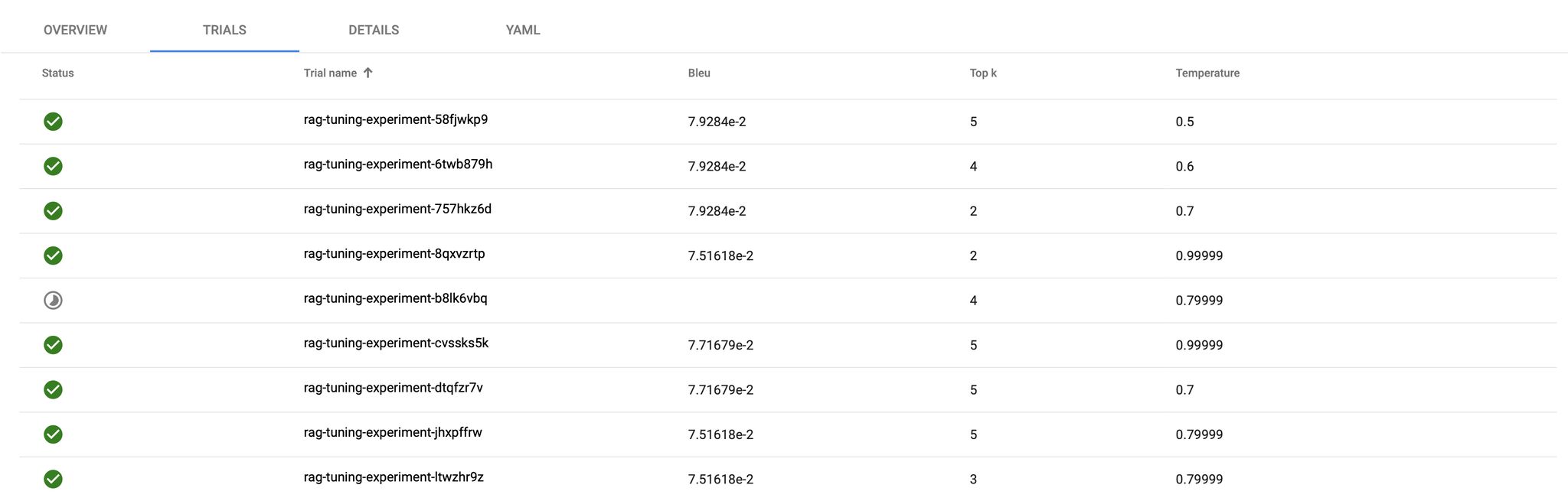
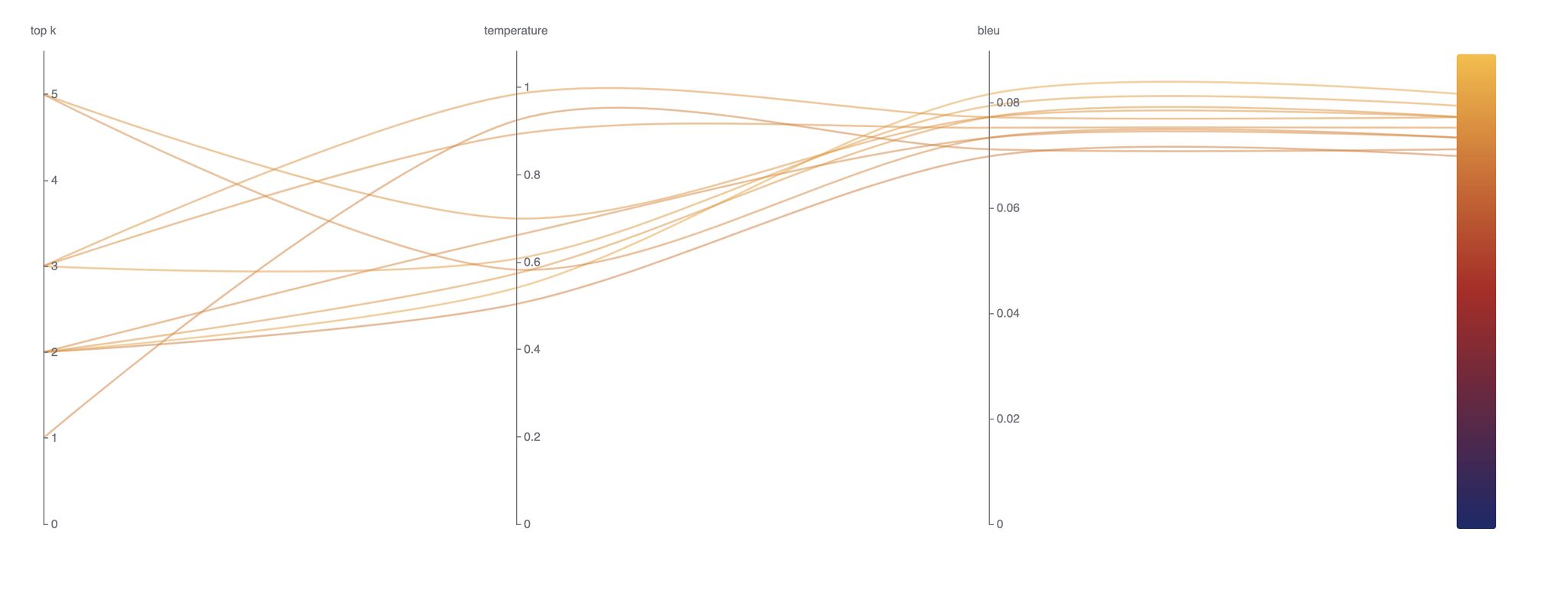
Conclusion
In this experiment, we leveraged Kubeflow Katib to optimize a Retrieval-Augmented Generation (RAG) pipeline, systematically tuning key hyperparameters like top_k and temperature to enhance retrieval precision and generative response quality.
For anyone working with RAG systems or hyperparameter optimization, Katib is a powerful tool—enabling scalable, efficient, and intelligent tuning of machine learning models! We hope this tutorial helps you streamline hyperparameter tuning and unlock new efficiencies in your ML workflows!