Kubeflow and Me: A Story Started with Push-based Metrics Collection
This summer, I gained a precious opportunity to participate in the Google Summer of Code(GSoC), in which I would contribute to Katib and fulfill a project named “Push-based Metrics Collection in Katib” within 12 weeks. Firstly, I got to know about GSoC and Kubeflow with the recommendation from the former active maintainer Ce Gao(gaocegege)’s personal blog. And I was deeply impressed by the idea of cloud native AI toolkits, I decided to dive into this area and learn some skills to enhance my career and future. In the blog, I’ll provide my personal insight into Katib, for those who are interested in cloud native, AI, and hyperparameters tuning.
Problem
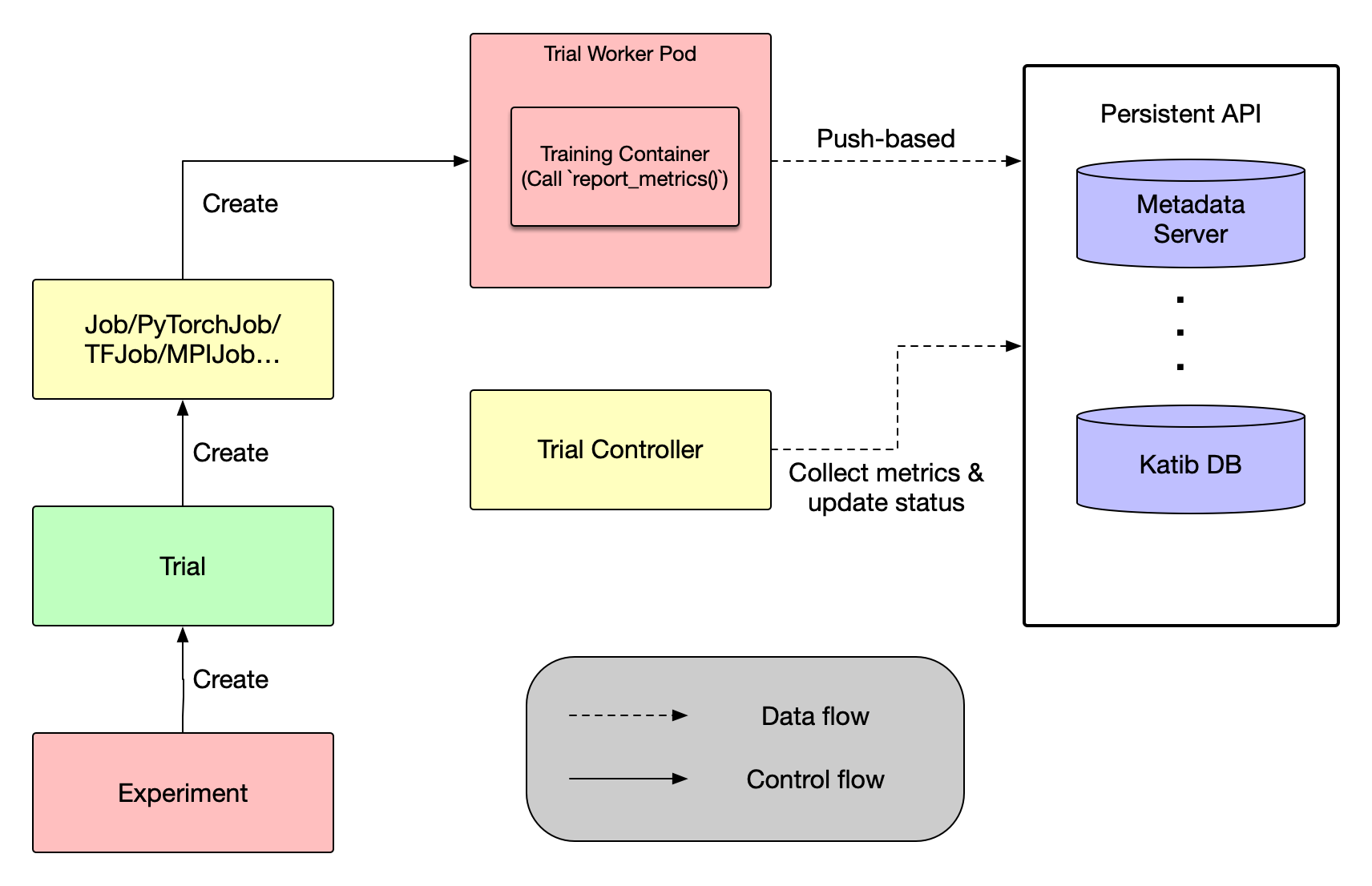
The project aims to provide a Python SDK API interface for users to push metrics to Katib DB directly.
The current implementation of Metrics Collector is pull-based, raising design problems such as determining the frequency at which we scrape the metrics, performance issues like the overhead caused by too many sidecar containers, and restrictions on developing environments that must support sidecar containers and admission webhooks. And also, for data scientists, they need to pay attention to the format of metrics printed in the training scripts, which is error prone and may be hard to recognize.
Solution
We decided to implement a new API for Katib Python SDK to offer users a push-based way to store metrics directly into the Kaitb DB and resolve those issues raised by pull-based metrics collection.
In the new design, users just need to set metrics_collector_config={"kind": "Push"} in the tune() function and call the report_metrics() API in their objective function to push metrics to Katib DB directly. There are no sidecar containers and restricted metric log formats any more. After that, Trial Controller will continuously collect metrics from Katib DB and update the status of Trial, which is the same as pull-based metrics collection.
If you are interested in it, please refer to this doc and example for more details.
My Contributions during the GSoC
I raised numerous PRs for the Katib and Training-Operator project. Some of them are related to my GSoC project, and others may contribute to the completeness of UTs (Unit Tests), simplicity of dependency management, and the compatibility of the UI component.
For reference, the coding period can be rougly divided into 3 stages:
-
Convert the proposal to a KEP and discuss the architecture, API design, etc. (~4 weeks) with the mentors
-
Develop a push-based metrics collection interface according to the KEP. (~8 weeks)
-
Write some examples and documentation & Present my work to the Kubeflow Community.
Also, I raised some issues not only to describe the problems and bugs I met during the coding period, but also to suggest the future enhancement direction for Katib and the Training-Operator.
There is a Github Issue tracks the progress of developing push-based metrics collection for katib during the GSoC coding phase. If you are interested in my work or Katib, please can check this issue for more details.
Lessons Learned
-
Think Twice, Code Once: Andrey taught me that we should think of the API specification and all the related details before coding. This can significantly reduce the workload of the coding period and avoid big refactor of the project. Meanwhile, my understanding of Katib got clear gradually during the over-and-over rounds of re-think and re-design of the architecture.
-
Dive into the Source Code: Engineering projects nowadays are extremely complex and need much effort to understand them. The best way to get familiar with the project is to dive into the source code and run several examples.
-
Communication: Communication is the most important thing when collaborating with others. Expressing your idea precisely and making others understand you easily are significant skills not only in the open source community but also in various scenarios such as at a company and in group work.
In the End
Special Thanks:
-
To my mentors @andreyvelich @johnugeorge @tenzen-y, especially to Andrey. Your great knowledge about the code base and the industry impressed me a lot. Thanks for your timely response to my PRs and for always attending the weekly meetings to solve my pending problems, from which I benefited a lot. What’s more, I can well remember that, in that night, you explained the usage of Kubeflow in the industry to me with greate patience, and encouraged me not to doubt about myself, just do it and explore more, contribute more. You ignite the flame of my desire to contribute to cloud native AI.
-
To @gaocegege. You recommend me to the Kubeflow Community. Thanks for your patient answers for my endless silly questions.
-
To Google. Thanks for offering such a precious opportunity for me to begin my journey in the open source world!
I hold a firm belief that every small step counts, and everybody in the community is unique and of great significance. There is no doubt that our joint efforts will surely contribute to the flourishing of our Kubeflow Community, make it the world-best community managing AI lifecycle on Kubernetes, and attract much more attention from the industry. Then, more and more new comers will pour in and work along with us.
Again, I’ll continue to contribute to Kubeflow.
Links
For more details about Kubeflow and the upcoming GSoC’25 event, please check: